
Recently, I took a job where I get to write go full time as a primary language. How did I get here?
A long time ago, I took a go tutorial at a Linux Conference in Australia. The tutorial lasted about 4 hours, and in that time I remember coming away with a vague idea that go was like a better C, with a stronger notion of types and concurrency and multiprocessing built in. It seemed useful, and I kept it pigeonholed there for a while.
When I first moved to the Bay Area, I had the task of learning Python sprung on me. As a career Perl programmer (as I saw myself at the time), I shrugged, and figured I would take up the opportunity to learn a new language. I didn’t know that it would turn out to be a change I would not look back from. Python was vastly better than Perl in ways that I did not expect. My feeling was that my code was a lot cleaner and maintainable. I embraced and even contributed new checks to PEP8, the style checking system for Python.
My mind was opened to the idea that some decisions languages make to restrict expressiveness (the touted superlative feature of Perl) could actually be net wins.
Flash forward to 4 years later, and here I am embracing go. To my pleasant surprise, there’s far more to it than “A better C”. There’s a better set of core language constructs than I’ve ever seen in a language. It’s also highly opinionated, and delightfully I’m finding I agree with its opinions. Strongly enough to revitalize my blog and repost it with a meaningless yet hip comment like “So very this”.
Gopinionated - So Very This
‘go fmt’ replaces space indents with tabs
With “hard” tabs, a person who prefers to look at code indented at 2 or 4 character stops can edit using their preference, without reformatting the code first with all the anti-social effects this can have if your reformatting changes escape into the wild. But at some point, hard tabs fell out of favor in certain language communities, and multiple spaces became preferred.
I once tried to get to the bottom of the idea that tab characters are a bad idea for initial line indents. The best I could find is that when you have a mix of tabs and spaces in a file, things can get out of whack when you change settings, line up with spaces and then submit patches to mailing lists. This breaks ‘diff’ output when sent to mailing lists. Maintainers accepting patches on mailing lists hate dealing with merge conflicts due to whitespace.
A second, minor reason could be that outside of your editor, your tab stop preferences might not be available.
But those justifications seem secondary to the benefit of allowing people to edit with their own settings. And most people are sharing directly through version control via pull requests, anyway, and the very few who still do will normally use a tool like git send-email directly.
This reinforces an opinion I have long held, that hating tab characters is one of those “Just So” things which touches a nerve in a lot of people, and so you just don’t question it because otherwise you’ll get yelled at.
It’s a small, perhaps trival thing. As it happens, some of my last significant Perl modules I released were indented with tabs, because in Perl there is more than one way to do it (TIMTOWTDI). I would never have done that with python, because the language has a style guideline that specifically requests 4 space indents. Which is one way to do it.
The optional comma is compulsory
This is another pet peeve of mine. If you are writing a multi-line list, or dictionary, then having a comma on the end of every line just makes sense. It means that adding new items to the end of the list is a single line insert. I don’t care what editor you’re using, that’s going to be a simpler edit than adding a comma on one line and then adding a new item on the line after it.
func main() {
fmt.Println(
"Hello",
"World" # no trailing comma
)
}
This is not just a style error, it’s a hard compile error:
./test.go:8: syntax error: unexpected string literal, expecting
semicolon or newline or }
In some languages, this comma is optional. In some, it’s prohibited. In JavaScript, it’s a bad idea in practice, due to, of course, Internet Explorer. The workaround for those languages where it is illegal in is awful:
myObject =
{ id: "1235"
, name: "Bob"
, address: "10 Downing St"
}
I could never bring myself to actually adopt that as a practice, because I saw it as a form of feeble language design protest.
In go, you either close the list or leave a trailing comma:
func main() {
fmt.Println(
"Hello",
"commas",
)
}
It’s possible that this rule makes the grammar simpler or faster or something, but personally I doubt that is the real motivation. I expect this is more about changing habits of the developers. The net result is that the line-based ‘diff’ and ‘patch’ approach of source code management tools give you better annotation, diffs and merging. And this is a public good worth sacrificing a little freedom for.
Matters of Gobstance - Core Language Design
I already passed over some things which are well known: Go is a compiled language, which gives you a lot of safety with a performance penalty you pay up front at compile time, instead of all the time while your program is running. It uses best-of-class parallelism which deserves its own post. But it goes beyond that to some small things I hadn’t noticed until using it for real. All without removing very useful features like closures.
Allocation efficiency
In Perl and python, the interpreters try to satisfy your string manipulation requests without re-allocating memory where possible. The way they do this is by creating under the hood, a bunch of pointers which refer to the original string. Perl even does this without making strings read-only, which makes for an “interesting” implementation under the hood. “interesting” as in the old apocryphal Confucian curse, “may you live in interesting times”.
In go, all of this is explicit. If you want to work with a substring of a string, you create a slice. And a slice is just a view on the original string. Unlike Perl or Python, you can write to those strings, and the slices get changed, too. And unlike these two langauges (and C), they’re a different type.
There’s a similar story with arrays: go requires you to explicitly allocate the size you need, and makes it clear when you are doing an operation (such as append, called push in Perl and JavaScript) which may re-allocate the list. You’re still free to code like that, and you’ll get degraded performance, like in a dynamic language. But it’s also possible to write faster code which avoids the allocator. Sure, you can achieve something similar with list comprehensions in Python, but if you end up needing to break that comprehension into an explicit loop, and pre-allocate your lists, you’re not writing idiomatic code any more.
For objects, the win can be even greater versus a dynamic language. Most dynamic languages back their object instances with some variation of a string map. Creating a single object can involve an initial allocation for the dictionary, an allocation for every object slot value, a re-allocation as the dictionary grows…
Avoiding memory allocation is a huge performance win. It’s often vastly underestimated how expensive allocating memory can be. Its performance can depend not on the amount of data you’re processing, but on things like how much work the program has done so far, and how fragmented the free list of your program is. And on languages without garbage collection, this could be slowing your code down in ways that are very hard to assess.
You can of course do all this in C, but people tend to shy away from it because it has the potential to blow up in your face when you don’t manage your object lifetime appropriately. But because you’re using a garbage collected runtime, you don’t have that problem. And Go’s garbage collection is really leading edge: it’s the kind which is able to largely operate in parallel with your main program execution. As of Go 1.5, when it does interrupt your program, on a typical system it will only do so for about 10ms: short enough to be hard to spot next to multi-tasking pre-emption.
As an example, there’s a library called fasthttp which avoids allocation during the request cycle and shaves off almost 20µs per request. Sound tiny, except it’s pretty impressive when you’re starting at 22µs. All by simply switching to an API which re-uses allocated objects.
Through my career I’ve watched computers get faster and programs run in about the same amount of time as the runtimes get more and more complex. But now I’m seeing people measuring their execution times in nanoseconds. My computer got fast again.
Interfaces, not inheritance
A long time ago, I had the pleasure of meeting Audrey Tang, who share her story of reading a book called Types And Programming Languages, which inspired her to create a mock-up implementation of the kitchen sink of languages, Perl 6. This book progressively walks through a pure functional basis for dealing with higher constructs in programming languages, and even dynamic language state. In chapter 14 or so, it’s demonstrating how objects can be expressed in terms of collections of functions.
At the time I was quite heavily invested in the Object-Oriented school of though. I had been applying the concept of inheritance to many different spaces. I thought that it was possible to describe all classes as descendent from one true base class, and that if you had enough time you could make any tree of classes, and arrange them so that they had a rational structure, without duplication of methods. This diagram shook this crazy idea out of my head:
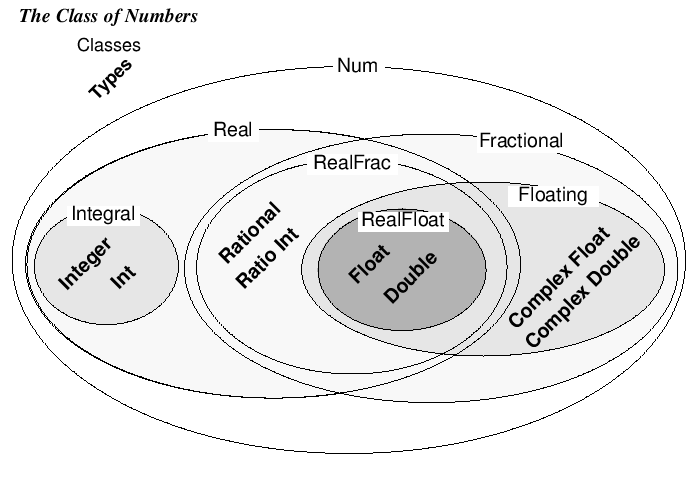
If simple number types could be so obviously non-tree-like, then of course, pure single-parent inheritance was not a true approach. So, what about multi-parent inheritance as in Python? What about Roles or Mixins, as you get in languages like Perl with Moose or Ruby?
The mistake is in thinking that because types have similar applications and similar implementations, that they are the same. The term is a, used by many object oriented languages, is not E Prime. This means it’s not specific enough: you’re implying some kind of inherant is-ness which you’re not defining. The only reasonable way to make decisions is based on behaves like a. Moose’s does approximates this, but requires classes to be built with the roles.
Go, on the other hand, has an approach much more similar to the pure functional approach seen in TaPL. It’s type-safe duck typing. You declare what you consider to be a duck, and then anything can be used for the function which satisfies your conditions. The class doesn’t need to declare it waddles and quacks like a duck when needed, it just has to waddle and quack. Instead of saying “this type is that type”, you can say “this type behaves like that type in these specific ways”. Removing the phrase, “to be,” from the sentence makes it E-Prime and therefore much easier to reason with.
In Go, you don’t inherit, you wrap the object you’re specializing, and then define your specialized methods. Instead of calling super, you just call the original method on the object you’re bundling. Unlike wrapping in a higher level language, it doesn’t need a whole new object: the allocation can often be bundled.
Reflection is core
By “core” here, I don’t mean that a reflection API is built into the language. A lot of languages have this: Java, for instance, does this very well. Perl’s core reflection API is completely bananas, using bizarre operators, but with Moose you can reflect over the Moose declarations a little bit more sensibly. Python has the beautiful type() operator, but you can’t reflect types on attributes because declaring value types is “non-pythonic”, so it doesn’t provide a way to do that.
Reflection without types is really just debugging the language’s data structures. This can be super userful, and one of the key things which make me much prefer Python to Perl.
But in Go, reflection is core in that the third argument to values declared in a struct are the reflection hints. They come right after the type:
type Foo struct {
Bar int `json:"byteAverageRead"`
}
I’ve now written two complex systems, for JSON and XML marshaling, in Python (normalize) and Perl with Moose (PRANG) respectively. A lot of the work, complication and expense of the implementation comes in building and operating the infrastructure for holding that attribute metadata. And a lot of complexity in the marshallers come from having to handle the case where the other programmer feels they shouldn’t need to provide a type hint.
In Go, both the metadata and types are center stage. Types are compulsory, and the attribute metadata is the next most important thing. All other fluff is completely gone. It seems so very, very right.
Generics are not the compiler’s problem
There’s a huge amount which has been written on this, but in Go, the only generic types are “map” and “array”. You can’t declare custom ones, and Silicon Valley’s brightest minds have basically come to the opinion that you can’t have these in the compiler without introducing a penalty, either in compile/link time as in C++, or at runtime as in Java.
From my reading of the various discussions surrounding this topic, it seems likely that there will evolve to be some kind of very much simplified templating construct emerging as the way forward. I very much like the approach in insert ref here, where you declare a generic by writing the version which pays the penalty at runtime, using interface{}, and when you want a more optimized, typesafe version, you import it using a special syntax which writes out the templated code during compilation.
Excluding generics lets the compiler, and your program, scream along.
Goriffic utilities
godoc is the bees knees
One thing I missed in Python vs Perl was the tradition of perldoc(1). There’s a great tradition of starting modules by writing the “SYNOPSIS” section, which is something like Behavioral-Driven Design (BDD) for software modules. This tied well into CPAN, and its approach of allowing code interspersed with documentation via POD resulted in an ecosystem where in general there is good documentation.
Python has docstrings, which pydoc let you access (I always aliased pydoc='python -m pydoc'), as well as Sphinx. Sphinx is more sophisticated in some ways but also not as widely populated as perldoc MODULE. It does support building documentation from the code and docstrings, but it’s buggy and inflexible. This results in maintainers avoiding the features which pulls documentation from docstrings, breaking pydoc. The processing step is slow, and in general it’s up to the package maintainers to publish the sphinx documentation for a module publicly. If you’re offline or on an older version, you can generate sphinx documentation for the version of the module you have, or potentially for your entire ‘virtualenv’, but this is an arduous and slow task, definitely not seamless or widely practiced.
‘godoc’, on the other hand, minimally works as well as ‘perldoc’, and quickly takes you to the documentation you want. Even better, you can use godoc -http :6060, and then point your browser to localhost:6060, and browse auto-generated documentation for all of the modules you have installed! It’s like a magic, instant version of Sphinx.
go get HOST/PATH does a full clone
I find this to be such a good design decision and definitely comes from go’s birth in a world where everything is either developed or mirrored to git or mercurial. Because really, if you have a source dependency, what else would you want to do other than clone the source history?
Going the seeds of love
All of this has me very excited about the code I’m going to write: excited enough that I feel like making a blog about it. Gopefully, I’ll restrain from using go many neo-go-lisms with ‘go’, but I can’t promise anything.
The first set of articles I have relate to going beyond the core language of go: a bunch of things that as a programmer, you need to know to be effective in a language professionally. The core tutorials cover the core language, but generally stop before discussing important things like writing tests or walking you through their standard library. But every programmer needs to know these things to be effective. I won’t assume anything more than that you’ve completed the Tour of Go.