[note: this is preserved as one of my most influential and well-read pieces of writing. It was originally on
http://utsl.gen.nz/talks/git-svn/intro.html]
This article is aimed at people who want to contribute to projects which are using Subversion as their
code-wiki. It is particularly targeted at SVK users, who are already used to a work-flow that involves
disconnected operation, though this is a tiny subset of the workflows supported by the git suite.
Subversion users can skip SVK and move straight onto git-svn with this tutorial.
People who are responsible for Subversion servers and are converting them to git in order to lay them down to die are advised to consider the one-off git-svnimport, which is useful for bespoke conversions where you don't necessarily want to leave SVN/CVS/etc breadcrumbs behind. I'll mention bespoke conversions at the end of the tutorial, and the sort of thing that you end up doing with them.
This is quite different from the Git - SVN Crash Course on the Git home page, which is intended for people who are familiar with Subversion who want to work with Git mastered projects using Git.
A lot of this tutorial is dedicated to advocacy, sadly necessary. Those who would rather just cut to the chase will probably want to skip straight to Getting Git.
NEW 20th June, 2007: click on images to enlarge!
NEW 7th October, 2007: clicking the images to enlarge shows a gallery and I didn't even have to do anything, thanks to Hugo!
I hope you enjoy this tutorial.
Sam Vilain
This tutorial, though long, probably still needs lots of work, and I would appreciate any feedback people would like to give. Especially if it comes as a patch against a git clone http://utsl.gen.nz/talks/git-svn/.git ;-). Even just FIXME notes with feedback would be great.
- A big hole in this tutorial is actually working with git-svn; how to sanely handle things like merging, etc. I'm afraid I was never really a prolific contributor to SVN-hosted projects, so the tutorial is very sparse on instructions relating to this.
Contents:
- What!? Yet Another Version Control System? Why?
- Model Simplicity
- Good Visualisation
- Publishing your changes for others to pull
- Breaking free from the "star" merge pattern
- Sane Merging
- Feature branches - the "stable" development model
- The Ferrari features - speed, resilience, space
- Primer for non-SVK-savvy users
- Getting Git
- How to...
- ...fetch an upstream subversion repository...
- ...re-using someone else's git-svn conversion
- ...by checking out just the trunk from SVN
- ...by importing your SVK mirrors
- ...by importing the whole repository from Subversion
- ...relocate a checkout
- ...make a local branch for development
- ...make changes to your local branch
- ...correcting changes in your local branch
- ...track updates on the upstream Subversion server...
- ...by updating somebody else's git-svn tracking repository
- ...using git-svn against the Subversion repository
- ...keep your local branch up to date with Subversion
- ...commit back to Subversion
- ...send patches to mailing lists or RT instances
- ...merge changes
- Git's limitations
- Development model impedence mismatches
- What darcs has over git
- What Bazaar-NG has over git
- What Mercurial has over git
- What Subversion has over git
- Summary
- Epilogue on history rewriting
- Contributors
- License
What!? Yet Another Version Control System? Why?
This is an understandable retort, but somewhat off the mark: git is not (just) a version control system. Linus' initial announcement describes it thus:
... It's not an SCM, it's a distribution and archival mechanism. I bet you could make a reasonable SCM on top of it, though. Another way of looking at it is to say that it's really a content- addressable filesystem, used to track directory trees.
Well, time has gone on, and sure enough, a huge collection of people have written some nice Source Control Management (SCM) software that runs on top of git, and a lot of it is bundled with it. Yes, it's true that git is a re-invention of Monotone that Linus wrote while waiting for it to finish importing the Linux kernel from BitKeeper - but technically, it's a different class of software to the Version Control System. It's a filesystem.
We're at the point now where instead of a whole lot of people being happy that we've got a simple and efficient filesystem which competes with RevML but is XML free and therefore doesn't suck, you get a whole load of people who seem miffed that you're implying Subversion isn't the be-all and end-all of version control systems and choose to vent their spleen at the mention instead. This is why I'm spending all this time I'd much rather be using to hack writing this article.
Subversion added nothing to CVS' development model. Nothing. It just fixed bugs, and that was the plan all along. It's still the same broken, inflexible work-flow. It broke it further by flattening branches and even tags into the same namespace as your project's filesystem. It even tried to sell this as a benefit.
A lot of people will point at the failings of git - such as the lack of a decent Windows port. "harden up and install Cygwin" is always an handy answer to that one, but the MinGW port is coming along and there are even installers now! Other hand-waving arguments are made about their perception of such intangibles as the "cleanliness" of the implementation. Yes, it's a bunch of small programs that do one thing and do it well, get over it, they're being unified, in fact there's a completed GSoC project which made considerable headway on that. There's also a pure Java implementation, a pure C# implementation, a pure Python implementation (which integrates with Mercurial and bzr), two more Python implementations, as well as pure Perl, pure Ruby, pure Objective-C and even 'pure' PHP implementations. This is enough independent re-implementations for Git to get a fast-track Internet RFC.
But all these arguments are simply blown away by the benefits and the amount of energy going into git development. I've dedicated an entire section to these shortfallings, in fact, and I'll say now, it's not comprehensive.
I don't have any irrational hatred for Subversion or SVK, and I like the people behind them very much. They've done well at what they set out to do - but you can't make a silk purse from a pig's ear*, or carve rotten wood* for that matter. I used to push strongly for SVK, but got brow-beaten by people who were getting far more out of their version control system than I knew possible until I saw what they were talking about.
In a way, it's something of an irrelevant question - comparing apples with oranges - because SVK could easily use git as a backing filesystem and drop the dependency on Subversion altogether. So could bzr or hg. I started down this path, but decided again, I'd rather hack using a version control system than on a version control system.
Model Simplicity
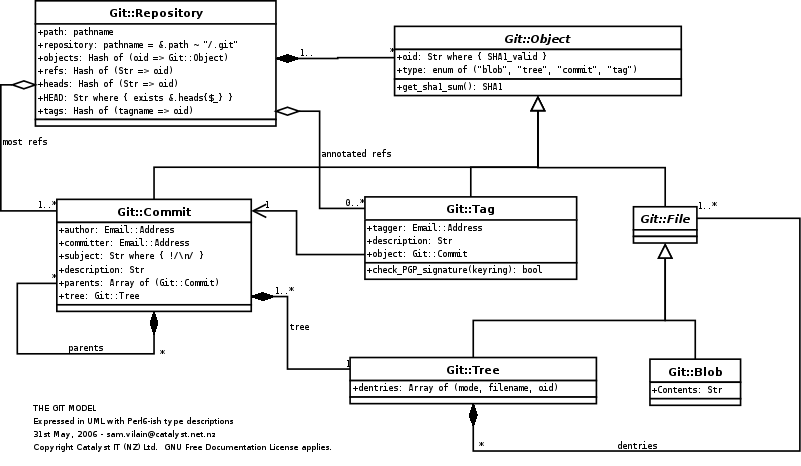
The core Git filesystem can be explained as four types of objects: Blobs (files), Trees (directories), Commits and Tags. The repository model (see right) is also simple enough that there are complete git re-implementations you can draw upon, in a variety of languages.
As I mentioned earlier, git is first and foremost a toolkit for writing VCS systems. As a result, one huge benefit is a flexibility and wide range of tools to choose from. Writing a tool to do something that you want is often quite a simple matter of plugging together a few core commands.
It's simple enough that once a few basic concepts are there, you begin to feel comfortable knowing that the repository just can't wedge, changes can be discarded yet not lost unless you request them to be cleaned up, etc.
Good Visualisation
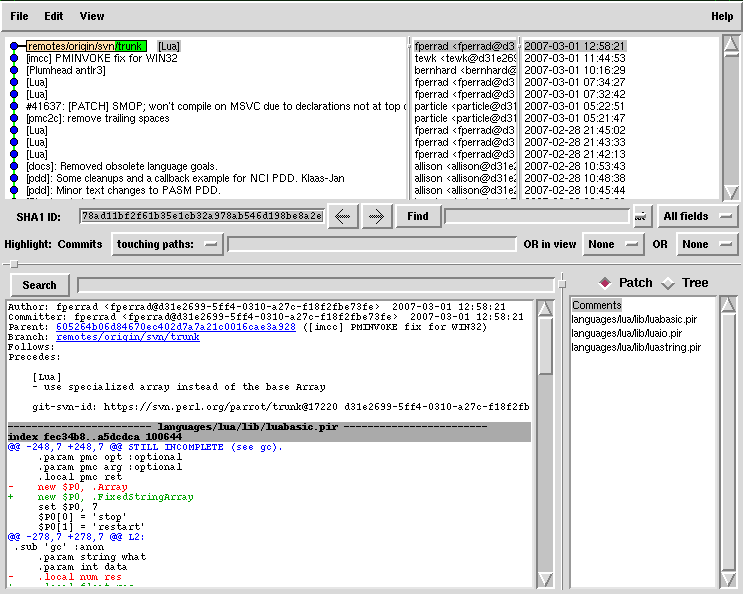
I really haven't seen a nicer tool than gitk for browsing a repository. It's so good that bzr and hg both stole it. You can crank open gitk on it and click on commits, see their patches and the state of the tree at that point in time.
$ gitk --all
gitk does some really cool things but is most useful when looking at projects that have cottoned onto feature branches (see feature branches, below). If you're looking at a project where everyone commits largely unrelated changes to one branch it just ends up a straight line, and not very interesting.
Publishing your changes for others to pull
You can easily publish your changes for others who are switched on to git to pull. At a stretch, you can just throw the .git directory on an HTTP server somewhere and publish the path. You don't need any silly Web-DAV extensions built into the web server just to share revisions. There's the git-daemon for more efficient serving of repositories (at least, in terms of network use), and gitweb.cgi to provide a visualisation of a git repository.
At Catalyst, NZ's largest Open Source Software Services company, most of the time even when we're committing changes back to an upstream project server, it goes to our public git server as well. We just consider it good practice - all of the work we do we can share with everyone easily, and crucially the politics about what goes in and out of a project simply goes away - you can't stop me from publishing changes to your project in my own space. Am I the master or you the master? That's not for you to decide, it's for the users to decide who they track. But hopefully we can work together.
There are sites out there like repo.or.cz, Gitorious or GitHub which will let anyone start a new project (or publish their fork of an existing project, or pull an interesting fork they found into the service). A network of these repositories is kind of like a decentralised, peer-to-peer source network - there's even a protocol designed for synchronising them.
With Subversion, everyone has to commit their changes back to the central wiki, I mean repository, to share them. SVK claims on its home page to be distributed, but by everyone else's definition, it's not, because it's not decentralised - there's always an upstream. No, SVK merely offers disconnected operation. If I meet you in the middle of a cruise and we both have a mirror of a subversion repository, I just can't easily, natively share my local branch with you if we're both on SVK.
With Git (actually this is completely true for other distributed systems), it's trivial to push and pull changes between each other. If what you're pulling has common history then git will just pull the differences.
So I'd just copy my repository to a USB key, stick it into the target machine, then run:
Sure, a USB stick isn't as gimmicky as a peer to peer wireless protocol featuring autodiscovery. But frankly I'll put up with that for sane branching support in the first place.
If the person publishes their repository as described above, using the git-daemon(1), http or anything else that you can get your kernel to map to its VFS, then you can set it up as a "remote" and pull from it;
Here we're configuring all of the heads (aka branches) of the repository which appears at /net/friend/git/project to appear as remotes/friend/XXX in our repository.
This is your cross-branch merging:
This is your cross-branch merging on drugs, I mean, with Subversion:
Look at the merge commit in the top diagram - it has two lines coming back from it. It has two parents. It's something equivalent to SVK's merge tickets. SVK had a design caveat, if you were not merging in upstream branches then when pushed back to a server, the merge tickets became worthless to others because they had the repository UUID and revision in the merge ticket. So someone would see "so-and-so merged in revision 23,632 from repository <random string>". Whoops! By contrast, with pre-SVN 1.5 merging (and let's face it, SVN 1.5 was released so late as to be irrelevant) you have to hope the merge has some key word in it like "merge" or "sync" or "merging" or something like that. Or people roll half-baked systems to track it as in the above picture? Can you spot the commit where the merge happens? I couldn't.
This is an interesting one. Most people say "but I don't want branches". But users of darcs report that they didn't know how much they really did want branches, but never knew until darcs made it so easy. In essence every change can behave as a branch, and this isn't painful.
Because you can easily separate your repositories into stable branches, temporary branches, etc, then you can easily set up programs that only let commits through if they meet criteria of your choosing. Because you can readily work on branches without affecting the stable branch, it is perfectly acceptable for a stable branch to be updated by a single maintainer only, even for busy projects.
Some repositories, for instance the Linux kernel, run a policy of no commit may break the build. What this means is that if you have a problem, you can use bisection to work out which patch introduced the bug. While this might be possible with Subversion, there's no guarantee that the intermediate versions will build, and no easy way - short of pre-commit hooks - to ensure that this is the case.
You might use a continual integration server that is responsible for promoting branches to trunk should they pass the strictures that you set. You might make a rule that the branch must be marked as mergeable, merge cleanly against trunk, add tests, and all tests must still pass.
Your "trunk" becomes merely a point where branches considered stable are merged into. Each of your feature branches can merge from the trunk easily, which means that an immediate merge back in the other direction will involve no actual changes (no extra commit will be made in such a case - the head pointer will just be moved).
With git, you really can commit early, commit
often. There is an awful lot less to keep in your head, and you
don't have to do things like plan branching in advance. You can
just hack it out, then straighten it out later.
Good feature branches mean you end up prototyping
well-developed changes; the emphasis shifts away from making
atomic commits. If you forgot to add a file, or made some
other little mistake, it's easy to go back and change it. If you
haven't even pushed your changes anywhere, that's not only fine, but
appreciated by everyone involved. Review and revise
before you push is the counter-balance to frequent commits.
Self-review, as well as peer review, help make changes more
understandable, catching bugs sooner.
Resilience - Your git server going down doesn't kill your
team's group development. Each person can just throw their branch
in a web server, a repo fork, and
easily track each other's repositories. They just stop pushing to
the nominal "central" branch and push to each other for a bit.
Speed - git is very fast for the most common use
cases. Yes, there are operations for which the model is less
efficient than, say, Mercurial in terms of antiquated measures such
as discrete disk IOs. But in general git wins.
Not only is the implementation fast locally, it's very network
efficient, and the protocol for exchanging revisions is also very
good at figuring out what needs to be transferred quickly. This is
a huge difference - one repository hosted on Debian's Alioth SVN server took
2 days to synchronise because the protocol is so chatty.
Now it fits in 3 megs and would not take that long to synchronise
over a 150 baud modem.
Disk might be cheap, but my /home is always full -
git has a separate step for compacting repositories, which
means that delta compression can be far more effective. If
you're a compression buff, think of it as having an arbitrarily
sized window, because when delta compressing git is able to match
strings anywhere else in the repository - not just the file
which is the notional ancestor of the new revision.
This space efficiency affects everything - the virtual memory
footprint in your buffercache while mining information from the
repository, how much data needs to be transferred during "push" and
"pull" operations, and so on. Compare that to Subversion, which
even when merging between branches is incapable of using the same
space for the changes hitting the target branch. The results speak
for themselves - I have observed an average of 10 to 1
space savings going from Subversion FSFS to git.
I'm going to be referring to a lot of SVK commands through this, but for Subversion users, here's a quick introduction to SVK concepts. SVK users can skip this section and go onto getting git.
Breaking free from the "star" merge pattern
$ git pull /media/usbdisk/project.git
...
$
$ git remote add friend file:///net/friend/git/project
$ git fetch friend
Sane Merging
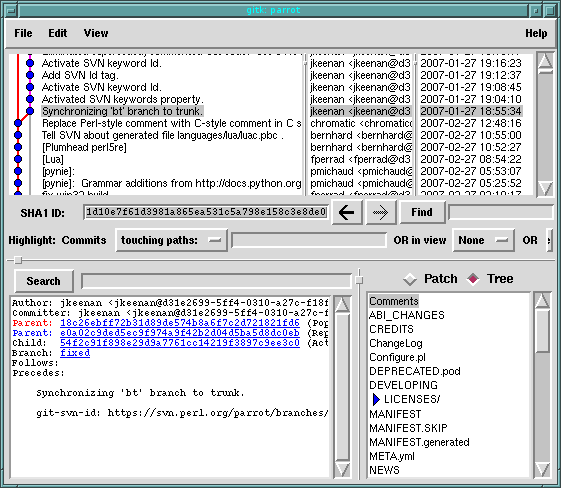
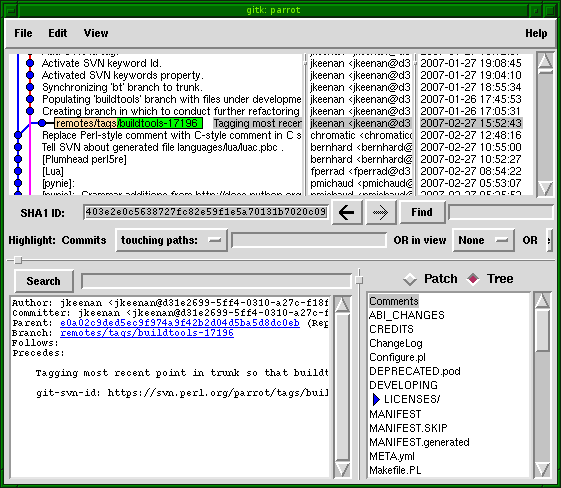
Feature branches - the "stable" development model
The Ferrari features - speed, resilience, space
Primer for non-SVK-savvy users
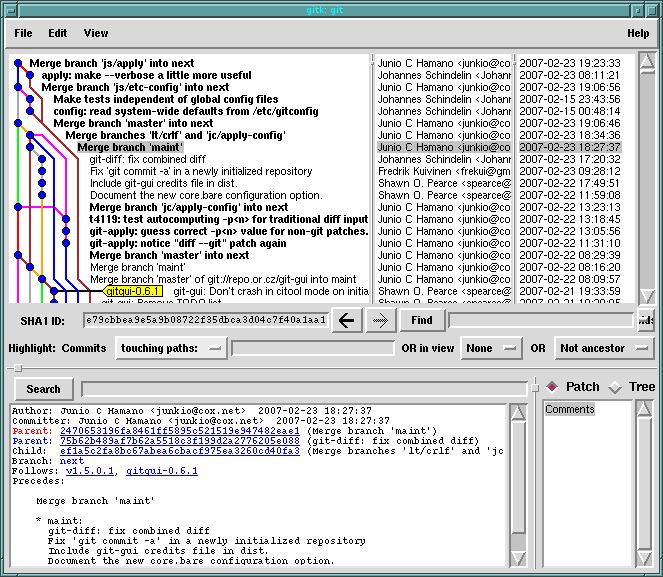
Getting Git
Get yourself a copy of some fresh sources - git is a rapidly progressing project, the versions from the home page are probably going to be better than the ones you'll find in your distribution (depending on how old this tutorial is when you read it). Version 1.5.0 or higher is recommended. Note that in Debian you'll want git-core.
If you are going to want to try importing your SVK mirrors to git, you should start with a version that includes the appropriate SVM-related features. It probably won't take long for these to hit the regular git, but at the time of writing you'll need to get a snapshot from Eric's branch. Update: or git 1.5.1+ :-)
I'm not going to talk about how you build and install it, it's just like every other application out there. It's only got one "nightmare" dependency (asciidoc), that's only used for building the documentation. In lieu of doing that, you can just read the text files in the source distribution under Documentation/. You should also install a recent Tk for the GUI that will change the way you look at version control forever (as an aside, did you know that Tk doesn't have to look butt ugly?)
Well, that's core git. git-svn, by nature, also depends on the same crazy stack of Apache innards and Subversion SWIG bindings that SVK does. However, these can be any version.
How to...
...fetch an upstream subversion repository...
You are at a junction with many roads, all leading to the same destination.
The first is labeled "the fastest route", with some graffitti that looks like it says "CHEAT!". At the end of the road you see a well-preened parrot. Follow this road to download an already-imported git-svn repository quicker than you can say "svk co https://svn.perl.org/parrot".
A second path labeled "check out SVN trunk head revision" looks quite short, but there's only the head of the Parrot at the end of it, and it looks very muddy.
There's a sign leading into the forest saying "import our existing SVK mirror paths", with "1 hr return" (those times are always exaggerated anyway, you know it's only 30 minutes for someone as fit as yourself). You'll need your SVM-enhanced git (1.5.1+) to proceed further.
The fourth sign points back to the quagmire you are leaving and says "import the entire Subversion repository from the source", with "2 days" written underneath.
Life's full of choices, which path is for you?
...re-using someone else's git-svn conversion
Perhaps somebody has already made a conversion of the project and put it somewhere like the repo.or.cz.
If so, once you've found it, you can check out the entire history of the project with:
$ git clone git://github.com/gheift/parrot.git Initialized empty Git repository in /home/samv/tmp/parrot/.git/ remote: Generating pack... remote: Done counting 152636 objects. remote: Deltifying 152636 objects. remote: 100% (152636/152636) done Indexing 152636 objects. remote: Total 152636, written 152636 (delta 102789), reused 152478 (delta 102789) 100% (152636/152636) done Resolving 102789 deltas. 100% (102789/102789) done Checking files out... 100% (2990/2990) done $
Great! Didn't take long, and that was the same as the whole svk co sequence - add mirror, sync revisions, and checkout. If you are close enough on the network to github.com, that may have taken less than a minute. You can proceed to using your git-svn git repository, below, if you just want to play with it and not worry about the painful migration part.
Of course if the upstream Subversion repository is down and you don't have an SVK mirror then this is your only option.
...by checking out just the trunk from SVN
It is probably second fastest to just check out the SVN head using git-svn; this is a bit like setting up a mirror path with svk mirror, then syncing only to the head revision using svk sync -s NNN (where NNN is the head revision, found below using svn log):
$ svn log https://svn.perl.org/parrot/trunk|head
------------------------------------------------------------------------
r17048 | bernhard | 2007-02-19 07:32:13 +1300 (Mon, 19 Feb 2007) | 3 lines
Remove the PIR.pg and bc.pg examples as they are
now covered by languages/abc and languages/PIR.
------------------------------------------------------------------------
r17047 | bernhard | 2007-02-19 07:09:00 +1300 (Mon, 19 Feb 2007) | 5 lines
[languages/PIR]
$ mkdir parrot
$ cd parrot
$ git svn init https://svn.perl.org/parrot/trunk
Initialized empty Git repository in .git/
git-svn Using higher level of URL: https://svn.perl.org/parrot/trunk => https://svn.perl.org/parrot
$ git-svn fetch -r17048
A DEPRECATED.pod
A debian/libparrot-dev.install
A debian/parrot-doc.install
...
A examples/streams/ParrotIO.pir
A examples/streams/Include.pir
A examples/streams/Filter.pir
r17048 = a57c09abef48d73f3c74c6a307793301b5956bfd (git-svn)
Checking files out...
100% (2959/2959) done
Checked out HEAD:
https://svn.perl.org/parrot/trunk r17048
$
Well, that was almost as quick - under 2 minutes for a head checkout; it had to download about as much as a release tarball. If you like, from here you can proceed to using your git-svn git repository.
But people who use git are used to treating their repositories as a revision data warehouse which they use to mine useful information when they are trying to understand a codebase.
We clearly can't do that with this shallow copy, but once your git-fu is strong, you can see you can graft parts of history from place to place if you want to, using history rewriting. I'll briefly mention grafting (and its drawbacks) later on.
...by importing your SVK mirrors
So, it is better to have the complete project history converted, but you probably won't want to wait the day or two it can take to replay a moderately sized Subversion repository using SVK (can anyone mirror the 40GB KDE Subversion repository?).
Be sure to see the notes above on getting an SVM-enhanced git.
First, svk mi -l will tell us where the mirror paths are.
$ svk mi -l | grep parrot /parrot/master https://svn.perl.org/parrot $
That's everything we need to get started. Now we just need to convert /parrot/master to an SVN url; the depot is everything up to the second "/", and most SVK users will just be using a single depot with an empty name, //. This example uses the depot /parrot/.
$ svk depotmap -l | grep '/parrot/' /parrot/ /home/samv/.svk/parrot $
So, I take the depot path and add on the rest of the mirror path, I should be able to look at the path using plain svn;
$ svn pl file:///home/samv/.svk/parrot/master Properties on 'file:///home/samv/.svk/parrot/master': svm:source svm:uuid svk:merge $ svn ls file:///home/samv/.svk/parrot/master branches/ tags/ trunk/ $
Great! The pl (proplist) command was important - the properties there, particularly svm:source and svm::uuid, must be there for git-svn to convert this repository correctly. We use the --use-svm-props option to set up the repository rewriting:
Set up the fetch using git svn init:
$ git svn init -t tags -b branches -T trunk \
--use-svm-props file:///home/samv/.svk/parrot/master
Initialized empty Git repository in .git/
Using higher level of URL: file:///home/samv/.svk/parrot/master => file:///home/samv/.svk/parrot
$
git-svn is quite capable of tracking multiple Subversion repositories that hold mirrors of the same project, though of course probably most people actually doing that are SVK users, and the "other repository" is your local depot. The above command set up a git-svn remote with the default name of "svn". Take a look at what was configured by running cat .git/config.
$ cat .git/config
[core
]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[svn-remote "svn"]
url = file:///home/samv/.svk/parrot
fetch = trunk:refs/remotes/trunk
branches = branches/*:refs/remotes/*
tags = tags/*:refs/remotes/tags/*
$
There are some important things to note here. Git's a simple system, and so take note of the refs/ paths - they're what git uses to refer to things in the repository. "Branches" are normally called refs/heads/foo, "tags" refs/tags/foo. In this case, we've got a special type of thing in our repository - "remote" references, which live under refs/remotes/foo. Actually, they will all be available locally, the tool is just keeping them tidy. Putting them under remotes gives us a different set of defaults for some commands.
Next, we can use git svn fetch to import them.
$ git svn fetch --repack 1000 --useSvmProps
A README
r2 = 5c2dbc76df3fc7569d0b779841427d5ddf406e9d (trunk)
M README
r3 = 9aa2f03a26ed9617cf7002bbe4acae5d3d24dadf (trunk)
...
$
So once that's all complete what did we win so far?
$ du -sk //home/samv/.svk/parrot .git 353576 //home/samv/.svk/parrot 155245 .git $
Well, that's a bit of savings. git saved half the space compared to Subversion fsfs. But it turns out that a lot of it is just git-svn metadata. And we can compress it more; I've got CPU to burn so I ran this command:
$ git repack -a -d -f --window 100 Generating pack... Done counting 131402 objects. Deltifying 131402 objects. 100% (131402/131402) done Writing 131402 objects. 100% (131402/131402) done Total 131402 (delta 99440), reused 31385 (delta 0) Pack pack-079a95f55810fc1eea600bc89c911a2bf85c1add created. $ ls -l .git/objects/pack/ total 33745 -r--r--r-- 1 samv samv 3154712 2007-02-20 16:00 pack-079a95f55810fc1eea600bc89c911a2bf85c1add.idx -r--r--r-- 1 samv samv 31360284 2007-02-20 16:00 pack-079a95f55810fc1eea600bc89c911a2bf85c1add.pack $
You may be wondering, "353MB of Subversion repository squeezed into 31MB of git pack? That's smaller than an SVN head checkout! Have not all the revisions been copied? Did something get missed?"
It turns out that git is just being incredibly space-efficient. More incredible stories about shrunken repositories can be found all over the internet. Talk to the GCC, Mozilla and KDE folk for the most impressive ones.
Now, in theory, we could keep using SVK to mirror revisions, and keep using git-svn fetch to copy them into the git repository. But we want some more space on our laptop to hold more MP3s, so we'll eventually delete it. Ideally we also want to convert our local branches - stay tuned for git-svn extensions aimed at making this smooth, or help out and submit a patch!
...by importing the whole repository from Subversion
This procedure is the same as the SVK one above, but we can just use the published repository URL.
$ mkdir parrot $ cd parrot $ git svn init -t tags -b branches -T trunk https://svn.perl.org/parrot Initialized empty Git repository in .git/ $ git svn fetch ...
I didn't test this one - I have already waited the many hours it took to sync the first time. Doing this for FAI took days. And the repository had the sheer indencency to end up tiny.
If you like, you can skip early revisions using the -r option to git-fetch.
...relocate a checkout
Unlike SVK, with git you don't need to do anything special to relocate a checkout, and you don't need to "detach" checkouts you no longer care about.
This is because git normally stores its repository information under .git at the top level of your checkout. But everything's compressed and the filenames don't resemble the files in your checkout so grep -r and find etc don't hate you. You can set GIT_DIR to get all the tools to look somewhere else if you really care, but for most people this system works very well. GIT_DIR doesn't work the same as SVKROOT in SVK, it's a per-checkout path, not pointing to a central place.
I don't know about you but I was always running into situations where my ~/.svk/config didn't match reality, and there were no breadcrumbs left in the checkout to do anything with it. I much prefer these floating repositories and there was some talk of adding them to SVK.
...make a local branch for development
One of the nice things about git (and darcs and bzr and ...) is that to make branches is not just "simple" it's trivial.
If you've got a version checked out that you want to work on - regardless of whether you've got local changes or not, you can use:
$ git checkout -b foo Switched to a new branch "foo" $
The name "foo" is completely private; it's just a local name you're assigning to the piece of work you're doing. Eventually you will learn to group related commits onto branches, called "topic branches", as described in the introduction.
But what does a branch mean? First we can explain it in terms of making complete clones of the repository, such is the only way of working with branches with some systems (such as Bazaar-NG and Mercurial, though Mercurial's overlays are somewhat similar).
Say you want to take a project, and work on it somewhere else in a different direction, you can just make a copy using cp or your favourite file manager. Contrast this with Subversion, where you have to fiddle around with branches/ paths, svn cp, svn switch, etc, if you're using SVK worry about whether you branch on the mirror path or the local path and what effect that would have for later merging, etc. And put up with Subversion followers saying that was 'natural' and 'easy'. Uh-huh.
$ cp -a parrot parrot.my-branch $
Each of those copies is fully independent, and can diverge freely. You can easily push and pull changes between them without tearing your hair out.
So, here's the deal. Each time you have a new idea, make a new branch and work in that. If this sounds like a scary suggestion, it's because you're still thinking too much of things in terms of the way Subversion works.
But anyway, that copying was too slow and heavy. We don't want to copy 70MB each time we want to work on a new idea. We want to create new branches at the drop of a hat. Maybe you don't want to copy the actual repository, just make another checkout. We can use git-clone again;
$ git clone -l parrot parrot.my-branch Initialized empty Git repository in /home/samv/.svk/parrot.clone/.git/ 0 blocks Checking files out... 100% (2815/2815) done $
The -l option to git-clone told git to hardlink the objects together, so not only are these two sharing the same repository but they can still be moved around independently. Cool. I now have two checkouts I can work with, build software in, etc.
But all that's a lot of work and most of the time I don't care to create lots of different directories for all my branches. I can just make a new branch and switch to it immediately with git-checkout:
$ git checkout -b localbranch remotes/trunk $
But wait, you say, don't I have to enter a commit message for this new branch?
Well, a branch in git is just a pointer to a commit. If you look at "gitk" now, you'll see a new green label on the same commit as "remotes/trunk" called "localbranch". They're like little "post-it" notes - with a new enough gitk you can pepper your history with them wherever you like with a click and then typing the name in. Hence terms like heads, branch tips, head references, refs/heads/, etc.
They generally don't form a part of the permanent history - it's the actual commits, the changes to the code, that are the history. Git does also track the movement of branch tips, but this is generally considered uninteresting and not synchronised or even recorded by default.
...make changes to your local branch
Once you have some edits you want to commit, you can use git-commit to commit them. Nothing (not even file changes) gets committed by default; you'll probably find yourself using git-commit -a to get similar semantics to svn commit.
This is because git has a powerful concept of a staging area, called the index, which is where you can prepare your changes before you actually save the commit.
$ vi CREDITS $ git commit -a committed tree 6b513546099f01826c5cc7bc25042d00bc2560b0 $
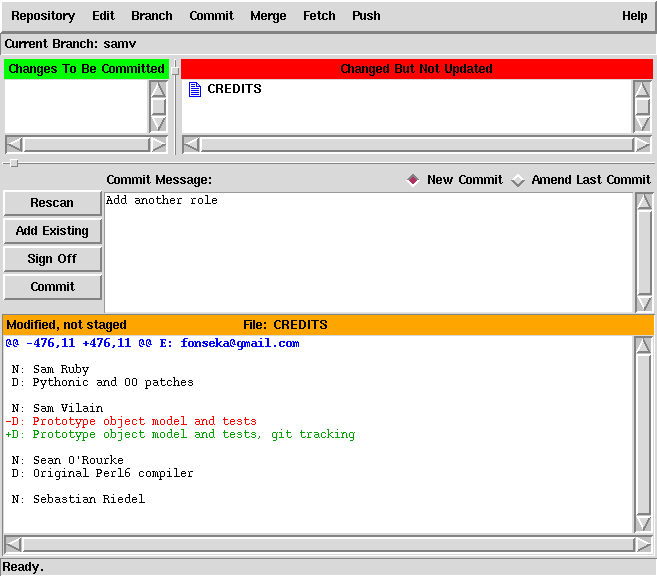
There is also a GUI for preparing commits in early (but entirely functional) stages of development. I'll mention it briefly, but personally I use the command line (or the vcs-git.el plug-in).
$ git gui
People used to darcs or SVK's interactive commit will like to try git add -p - it's more powerful than darcs record, though perhaps regrettably doesn't let you also commit via the same set of prompts.
...correcting changes in your local branch
Did you mess up a change? Commit something poorly? Well, no worries, there are lots of ways to fix it.
Again, we're diverging from things that SVK supports well, but I think they're important to get a taste for how things are different. According to one source, lack of support in SVK for this is a "philosophical" stance. I really don't understand this - I make mistakes all the time and it's better that I correct the ones I catch early so other people don't waste their time on them.
If it's the top commit, you can just add --amend to your regular git-commit command to, well, amend the last commit. If you explored the git-gui interface, you might have noticed the "Amend Last Commit" switch as well.
You can also uncommit. The command for this is git-reset
$ git reset HEAD~1 $
HEAD~1 is a special syntax that means "one commit before the reference called HEAD". HEAD^ is a slightly shorter shorthand for the same thing. I could have also put a complete revision number, a partial (non-ambiguous) revision number, or something like remotes/trunk. See git-rev-parse(1) for the full list of ways in which you can specify revisions.
And just like that, your most recent commit was unlinked. If it really was garbage, that was what you wanted. Actually, it isn't completely gone;
$ git fsck dangling commit 2ef718cf5434eeb8fdec74e69968f64fadd28761 $
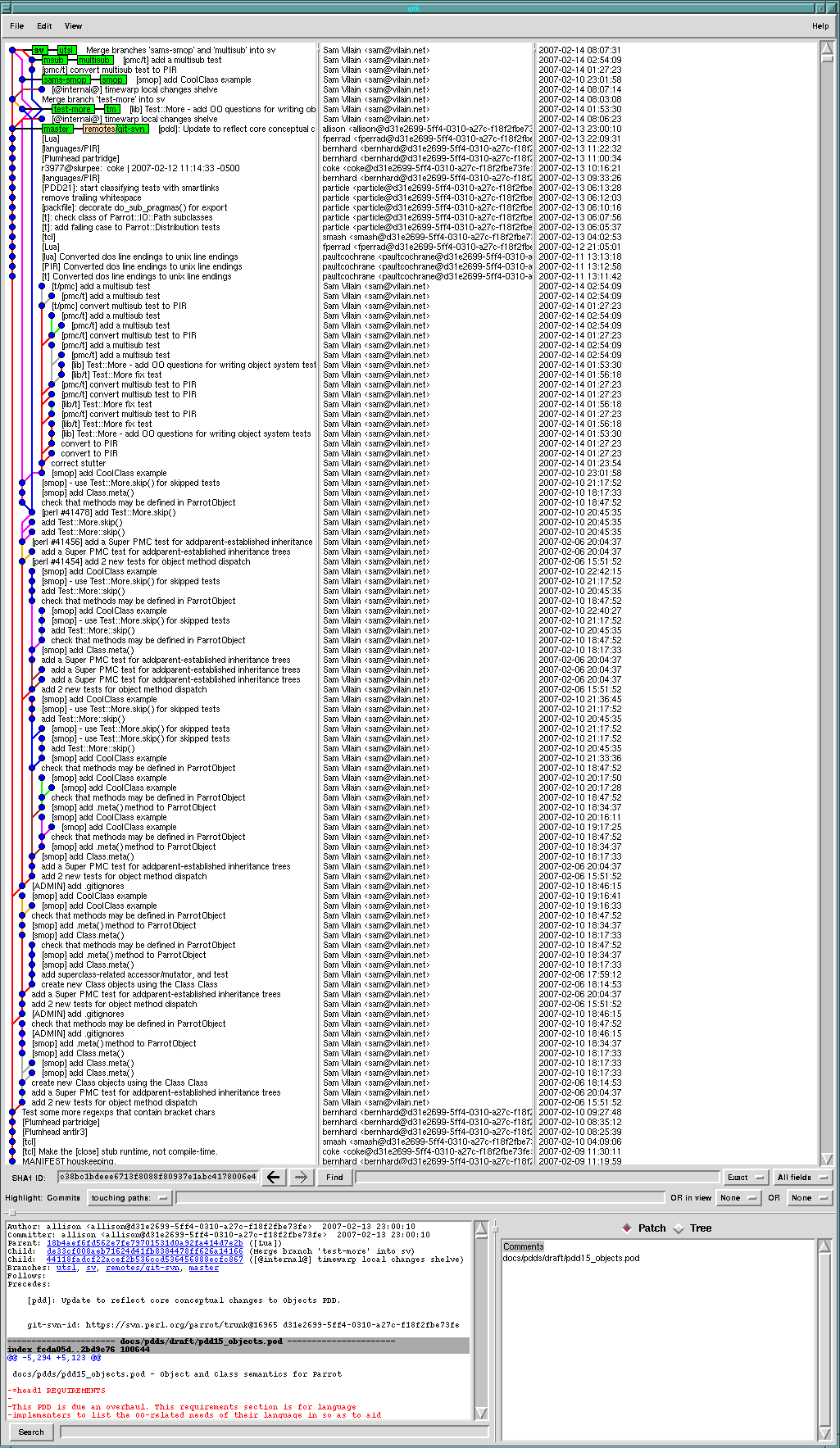
If you wanted, you could see it with, eg, gitk 2ef718. I sometimes write commands like `gitk --all `git-fsck | awk '/dangling commit/ {print $3}'`' to see all the commits in the repository, not just the ones with "post-it notes" (aka references) stuck to them.
But that aside, uncommitting really is a primitive mode of operation, and you'd probably end up getting confused by the fact that git-update-ref didn't change the index (staging area). This is because git-update-ref is a plumbing command; it does one thing, and does it quickly and well. Commands like git-commit are considered porcelain - that is, designed for user interface. So, the technical name for the above dangling commit is spillage. This analogy doesn't seem to extend far enough to make git-prune (which would delete that commit) called something like git-flush or git-pull-chain, however.
Initially, it was planned that Git itself would be just a toolkit for writing VCS systems, and that you would need to get your actual user interface from somewhere else. This is somewhat true; there are many programs which manage git repositories which are not distributed with git, and use only git commmands designated on git(1) as "plumbing". cogito was one famous early example of this. Cogito added many useful features and got quite a few users, however instead of augmenting the git-core command set, it replaced it entirely - and hence could not keep pace with the development of new features in git-core. From about git 1.5+, Cogito was considered deprecated, even by the original author. With git filter-branch (deriving from Cogito's cg-admin-rewritehist command) hit git-core, perhaps the only remaining feature Cogito has is the ability to clone a single branch from a repository in one command.
So, anyway, there are other tools for revising commits, and to be the king of patch revisioning is Stacked Git.
Say I discover a change that I actually wanted to apply three commits ago. Assuming that I haven't sent the patches out yet, then I can just go ahead and change them; no-one need know. I can anyway, it's just that the longer ago you change things the more antisocial the behaviour becomes, and some repositories won't let you push deletions to them.
In this scenario, we'll assume that what I'm currently working on isn't finished, either - and I don't want to have to finish it first. It's not ready. I'm just going to call it "WIP".
$ stg init branch 'localbranch' initialised $ stg new -m "WIP." new-commit ... $ stg uncommit -n 3 ... $
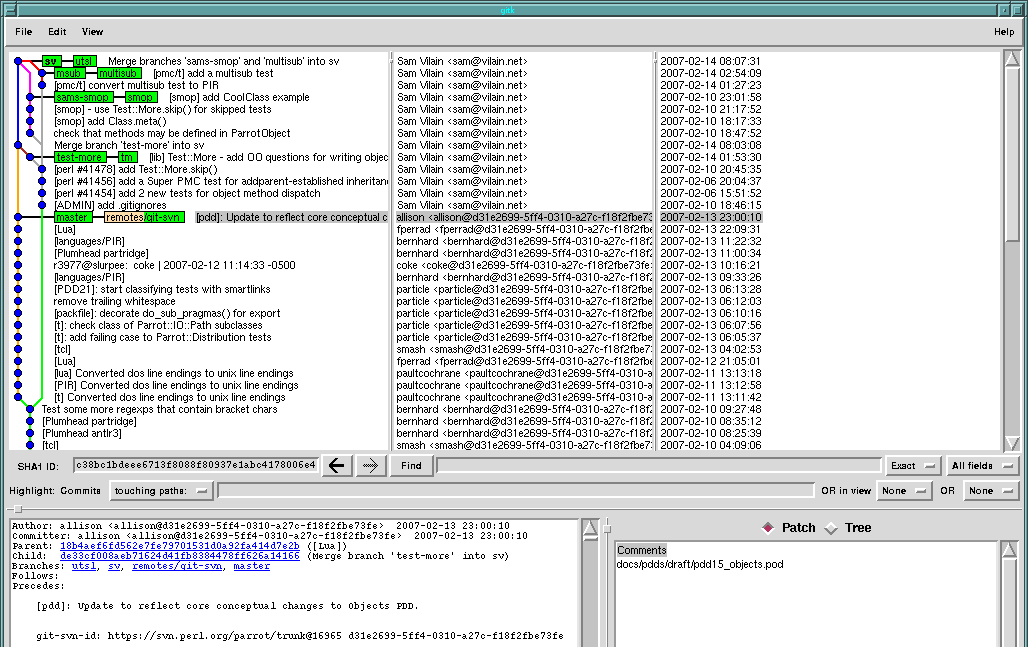
Now, stg uncommit didn't do the same thing as git-update-ref; specifically, it didn't change my working copy or the repository. They've just been moved onto the patch stack, which I can jump around with using stg commands. First I'll extract the current patch with stg diff, edit it, then apply it a few revisions up.
$ stg diff -r /bottom > this_commit.patch $ vi this_commit.patch $ stg pop -n 2 now at patch 'do_something_interesting' $ patch -p1 < commit.patch patching file foobar.c $ stg refresh $ stg push -n 2 now at patch 'do_something_else_interesting' $ stg commit $ stg push now at patch 'new-commit' $ vi foo.c $ stg refresh -e $ stg commit $ stg clean No patches applied $
But this isn't a tutorial on stacked git. See the Stacked Git homepage for that.
"Another" way to revise commits is to make a branch from the point a few commits ago, then make a new series of commits that is revised in the way that you want. This is the same scenario as before.
$ git commit -a -m "WIP." committed tree 5ef9339c5b5bc6572b69ff61cdb1dd4af4603f0b $ git checkout -b tempbranch HEAD~4 $ git cherry-pick --no-commit -r localbranch~3 ... $ vi foobar.c $ git commit -a $ git cherry-pick -r localbranch~2 ... $ git cherry-pick -r localbranch~1 ... $ git cherry-pick --no-commit -r localbranch ... $
I've introduced a new command there - git-cherry-pick. This takes a commit and tries to copy its changes to the branch you've currently got checked out. This technique is called rebasing commits. There is also a git-rebase command which probably would have been fewer commands than the above. But that's my way.
There are many, many ways to skin this cat. To tell the truth a lot of them don't play well together, hence commands like stg assimilate (to tell stg that you committed a change without telling it). It's the old Cathedral vs. Bazaar thing. Using Git opens the door to a bazaar of VCS tools rather than sacrificing your projects at the altar of one.
The design of git makes these situations easy enough to recover from in practice. Just don't run git prune or git repack -a -d unless you're sure everything that git fsck or git fsck --full (respectively) reports as "dangling" really is something you want to throw away.
...track updates on the upstream Subversion server...
There are of course multiple ways to track upstream updates, mostly depending on which road you took at that junction you found earlier.
If you chose the fastest route (cloning an already converted repository) it is possible to build on the work of others again. Or you can choose to return to the origins in case the work of others is not available.
If you chose the short road (checking out the Subversion trunk) it seems that you're stuck in the mud. It might be possible to clear through the mud a little bit further but it might be better to backtrack.
If you chose the forest (importing existing SVK mirror paths), there is a choice to be made: either you drop some things you picked up along the way that you do not need anymore, and then proceed, or you rely on your old ways (SVK) to provide you with directions before you continue.
Finally, while taking the long way (cloning using git svn) might not have won you the race, it did help at this junction -- your direction is pretty clear now.
...by updating somebody else's git-svn tracking repository
If you pulled from someone else who is tracking, you can update the latest Subversion revisions they've put there using the native git command git-fetch:$ git fetch remote: Generating pack... remote: Done counting 314 objects. remote: Result has 173 objects. remote: Deltifying 173 objects. remote: 100% (173/173) done Indexing 173 objects. remote: Total 173, written 173 (delta 146), reused 10 (delta 5) 100% (173/173) done Resolving 146 deltas. 100% (146/146) done 124 objects were added to complete this thin pack. * refs/remotes/origin/svn/trunk: fast forward to branch 'svn/trunk' of git://utsl.gen.nz/parrot old..new: e0a02c9..78ad11b $
This command completes very quickly even when pulling thousands of new revisions, modulo bugs for obscure corner cases like repositories with a huge number of non-overlapping revisions. You can configure what gets fetched with git-fetch by editing the repository config (have a peek into .git/config).
...using git-svn against the Subversion repository
Now for the other methods of keeping up to date, which all boil down to using git-svn in the end. Preparations might vary depending on your needs though, so read on.
Clearing git-svn metadata
If you converted the repository from your SVK depot, and you don't want to continue using SVK, then the safest thing to do is first clean out the git-svn metadata; but look out for git-svn updates that do this in a smarter way.
$ rm -r .git/svn $ vi .git/config $
Rebuilding git-svn metadata
If you copied the repository from somewhere else (eg, from repo.utsl.gen.nz) via git-clone, or if you just blew it away, then you won't have any SVN metadata - just commits. In that case, you need to rebuild your SVN metadata, for instance, for just keeping trunk up to date - git-svn will rebuild its metadata when you run git-svn fetch.
$ git update-ref refs/remotes/trunk origin/svn/trunk $ git svn init https://svn.perl.org/parrot/trunk Using higher level of URL: https://svn.perl.org/parrot/trunk => https://svn.perl.org/parrot $ git svn fetch Rebuilding .git/svn/git-svn/.rev_db.d31e2699-5ff4-0310-a27c-f18f2fbe73fe ... r17220 = 78ad11bf2f61b35e1cb32a978ab546d198be8a2e r17219 = 605264b06d84670ec402d7a7a21c0016cae3a928 r17218 = a8ceba9c503d2be8e8e69a3df454017322906cf5 ...
The key thing to remember with rebuilding git-svn metadata is to make the refs look just like they would look from a fresh import; you can do this using git update-ref as above, by copying refs files around inside .git/refs/, or using git pack-refs then editing .git/packed-refs. To test that you got it right, use git show-ref - perhaps compare with a fresh SVN HEAD clone.
Republishing git-svn clones
Git distinguishes between tracking branches and local branches based on the name of the ref. 'git branch -a' shows you shortened names; 'git show-ref' shows you them without such treatment.
When you clone a git repository, or when you clone an SVN repository using git-svn, the upstream will be under refs/remotes, not refs/heads. If you then go and simply copy the repository to a server somewhere, or use 'git push', then possibly only one branch will be sent.
To publish your tracking branch to another branch that someone can clone, you can specify the ref remapping using the remote.<remotename>.push git-config(1) setting; assuming you have a remote called github you can use:
$ git config remote.github.push refs/remotes/svn/*:refs/heads/* $ git config --add remote.github.push refs/remotes/svn/tags/*:refs/tags/* $ git push github ...
Actually this configuration is far easier to change via simple editing of the .git/config file. The refspecs (that's the refs/remotes/svn/*:refs/heads/* bit in the above) may look awkward, but they're quite natural once you understand how the full ref names work. Remember, git show-ref and git ls-remote are your friends here.
Fetching more revisions
If you have valid git-svn metadata, for instance pulled from the Subversion Server - the slowest option above - or you are continuing to use SVK to do the real fetching (and have just run svk sync), you would use:
$ git svn fetch
...
A examples/streams/Writer.pir
A examples/streams/SubHello.pir
A examples/streams/Combiner.pir
A examples/streams/ParrotIO.pir
A examples/streams/Include.pir
A examples/streams/Filter.pir
Successfully followed parent
W: +empty_dir: tags/buildtools-17226/compilers/past/t
W: +empty_dir: tags/buildtools-17226/compilers/post
W: +empty_dir: tags/buildtools-17226/docs/2.0
W: +empty_dir: tags/buildtools-17226/docs/ops
W: +empty_dir: tags/buildtools-17226/include/parrot/oplib
W: +empty_dir: tags/buildtools-17226/lib/Parrot/Config
W: +empty_dir: tags/buildtools-17226/lib/Parrot/OpLib
r17227 = f82d500d84c58664bb460df61277889f6003d4dd (tags/buildtools-17226)
$
...keep your local branch up to date with Subversion
The recommended way to do this for people familiar with Subversion is to use git-svn rebase. You actually don't need to use git-svn fetch separately; it will automatically fetch new revisions first.$ git svn rebase ... $
Note: before you do this, you should have a "clean" working tree - no local uncommitted changes. You can use git-stash (git 1.5.3+) to hide away local uncommitted changes for later.
This command is doing something similar to the above commands that used git-cherry-pick; it's copying the changes from one point on the revision tree to another, just like svk smerge -Il would. There is no analogue to this operation in plain Subversion.
Of course, in Subversion it is actually encouraged to do this without saving your changes first! In git, you commit first and ask questions later. So, to preserve the svn update semantics of allowing you to work when your working copy is changed, you can use these commands:
$ git-commit -a -m "Temporary commit" ... $ git svn rebase ... $ git reset --mixed HEAD^ $
Better still is to bunch up your in-progress working copy changes into a set of unfinished commits, using git add -i (or git-gui / git-citool). Then try the rebase. You'll end up this time with more commits on top of the SVN tree than just one, so using Stacked Git you can "stg uncommit -n 4" (if you broke your changes into 4 commits), then use "stg pop" / "stg push" to wind around the stack (as well as "stg refresh" when finished making changes) to finish them - see procode.org/stgit.
In fact in my experience stg is the best tool for rebasing, especially if you use a merging script like smartmerge (customise to taste if emacs isn't your thing). Once you grok that, you'll only need to use stg and git-svn fetch.
...commit back to Subversion
Ok, so you've already gone and made the commits locally that you wanted to publish back to the Subversion server. Perhaps you've even made a collection of changes, revising each change to be clearly understandable, making a single small change well such that the entire series of changes can be easily reviewed by your fellow project contributors. It is now time to publish your changes back to Subversion.
The command to use is git svn dcommit. The d stands for delta (there used to be a git svn commit command that has since been renamed to git svn set-tree because its behaviour was considered a little 'surprising' for first-time users).
git-svn won't let the server merge revisions on the fly; if there were updates since you fetched / rebased, you'll have to do that again.
People are not used to this, thinking somehow that if somebody commits something to file A, then somebody else commits something to file B, the server should make a merged version with both changes, despite neither of the people committing actually having a working tree with both changes. This suffers from the same fundamental problem that darcs' patch calculus does - that just because patches apply 'cleanly' does not imply that they make sense - such a decision can only be automatically made with a dedicated continual integration (smoke) server.
$ git-svn dcommit ... $
...send patches to mailing lists or RT instances
Again there are lots of ways to do this. Let's say we've made some changes and want to make patch files for all of the ones since trunk:
$ git format-patch remotes/trunk ... $
A command like git log remotes/trunk..HEAD would show you the commits that this involves. You can then take those patch files and attach them to e-mails or whatever. There's a command called git-send-email that takes patch files generated by the above and pushes them out to a mailing list.
A simpler way to pull out an individual patch is with git show COMMIT
If the project uses the kernel patch submission policy, which strangely enough is very similar to best practices for sending patches to usenet etc since 'patch' was invented, then you probably don't want to use --attach.
If the upstream applies your patch without changes, then if you later merge, the changes shouldn't need to re-merged. git will notice that there has been a revision since the "merge base" that an identical change was applied and realise it has already been done.
Unlike svk push -P, it's possible to work with a series of patches that build on each other, rather than just a single patch at a time. Fancy that.
...merge changes
This is normally what I use in preference to rebase.
$ git merge trunk ... $
This will merge all the commits that aren't in your ancestry, but are in the ancestry of the branch trunk (try setting rightmost drop-down in gitk to 'ancestor' and clicking around to get a feel for what this means), and make a new commit which has two parents - your old HEAD, and whatever commit trunk is up to.
If git's history-sensitive merging doesn't automatically resolve things like patches applied in a different order, you end up with conflicts. The local file gets conflict markers - which might sound apalling, but the "ancestor", "left" and "right" versions of the file are nearby, in the index (staging area). I like to use ediff-merge-files-with-ancestor to merge, so my merge script handles starting this for me to make merging easy. Far more effective than the emacs merge method I was using with SVK was. And I don't have to worry about breaking out of a merge aborting the whole thing and throwing away work.
No doubt some will say that SVK's UI is better because it lets you make per-file decisions as you make the merge. I see that as an easy possible addition to the git-commit interface. Submit a patch to the mailing list, and as long as it doesn't suck it will be included. It's just I've been quite happy to resolve using the facilities of the index.
Git's limitations
Of course if I didn't mention these then I'd have people ranting about how I was biased and partisan etc. But there are many shortfallings in git.Development model impedence mismatches
While git is a flexible development system, there are some development styles for which it does not do well.
The 'Smashing patches to pieces' development model
This is where instead of merging in patches completely, you merge bits of them in on a file-by-file basis, and expect the VCS to tell you later what you did.
Perforce tracks changes at this level, and Bazaar-NG can apparently represent this at the model level, but the authors have not found it necessary to provide the features to the users.
The 'Ghetto' development model
This is where you send new features into the ghetto so that they can 'battle it out'. The last features standing get re-integrated into another branch known as the trailer park to try to find a new life for themselves.
Note that ghetto is frequently called trunk, and the trailer park something like releng. The 'hood is frequently mis-spelled "head".
Sadly, this model is in use by virtually every Subversion hosted project out there. And that is going to be hard to undo.
What darcs has over git
Opportunistic topic branches

darcs has a very special idea about ancestry. To darcs, by default patches exist in time at the earliest point at which they apply cleanly. The crazy thing is, it figures this out at the latest time possible.
It is possible to use git in this way (see the figure comparing darcs with git - prepared using git) - but it's not trivial, and not default. In fact git itself is developed in this way, using feature branches, aka topic branches.
Interactive commit
git add -p fixed the main annoyance with git add -i - mainly that it didn't drop you straight into reviewing which changes to add into the commit. It's already more powerful and flexible than darcs record, but it would be nice if there was a git commit -p which wrapped that up (hmm, I feel a patch coming on...)
However, git does have GUI interface that can be used to stage commits - git gui is now my standard recommendation for those who want to commit just parts of their work.
Push changes and the working copy
With git, if you git-push into a repository that is not 'bare', ie, it has a checkout too, then something somewhat surprising happens; the repository is moved forward, but the checkout (and the index/staging area) isn't.
In darcs (and probably bzr), what happens is that both the repository and the checkout is updated, making push and pull symmetric.
You could in theory get around this with update hooks, but it seems no-one has cared about this enough to make this work yet. Everyone must just use pull, or they use git-remote correctly to push into remotes/ style references, therefore never updating a branch that is currently checked out. Update: looks like I care enough, and so I wrote such a git hook to update the working copy for managing this article.
What Bazaar-NG has over git
bzr comes with some great utilities like the Patch Queue Manager which helps show you your feature branches. With PQM, you just create a branch with a description of what you're trying to do, make it work against the version that you branched off, and then you're done. The branch can be updated to reflect changes in trunk, and eventually merged and closed.
Let's see, what else. Windows support is good. Consistent implementation. Experience with the distributed development model. Friendly and approachable author and core team. Mark Shuttleworth's bank balance.
Actually the models of git and bzr are similar enough that bzr could be fitted atop of the git repository model, with only a few subtle and unimportant impedence-mismatch related bugs creeping in. At least, that was the initial assessment when I talked this over with the bzr devs at OSDC in Melbourne. If that happened, then git really would be a common platform for sharing software revisions - kind of like RevML, but without the XML.
At OSDC Martin & Andrew also showed off an interesting continual integration console, only letting branches be merged to trunk if they pass tests and have been reviewed internally - but I won't count that because they haven't released the darned thing as open source yet. Well, I don't care. At least they're using it to produce some fine open source software that I can track easily with git.
What Mercurial has over git
It's worth linking to the Hg - Git Death Match from the Google Summer of Code Mentor Summit 2008, which has a few bulleted points about this. The presentation was prepared in the presence of core committers from both Mercurial and Git.
There are down-sides. Mercurial is missing lightweight branches that makes git so powerful. Its “named branches” and “bookmarks” are close, but remain forever in the history, without a cumbersome re-clone to clean-up. That is a trade-off by design due to the repository format, which is append-only. Because of this, it is not desirable for history to ever disappear. The repository format, not using content-based addressing, also misses out on many of the advanced git repository features such as arbitrary delta compression and many applications of git that extend outside of the version control system problem space. And to script it, you must write Python - the command line interface nowhere near as flexible (or complicated) as git’s. These downsides are perhaps why people like Ted T’so say “git has more legs”.
However as a version control system in its own right, it’s certainly one of the best. And if you consider that it is almost a twin brother of git, being written in response to Larry McVoy’s Great Temper Tantrum™ and its first release only a couple of weeks later than git’s first release, and given all that it has achieved, it’s an outstanding accomplishment.
Here are some of the reasons why.
Portability and Consistency
Mercurial, like Bazaar-NG, is written completely in Python (with some performance critical parts in C). So, if you like Python you might find that good. If you’re on Windows it’s probably a lot easier to get going. Hey, maybe it will even one day run on IronPython on .NET.
Optimisation for the Cold Cache case
In the “cold cache” case, git typically needs to load a lot of blocks to do some operations. Mercurial, on the other hand, gets away with far fewer seeks for them. This means it can be a lot faster - for instance, one use case that Mercurial is a lot faster is applying a ton of patches.
In the “hot cache” case, git typically blows Mercurial out of the water, except for operations where git is having to do searches to get the data, like annotate.
Bundle efficiency
Mercurial’s hg bundle does a really, really good job of making small packs. With the e2fsprogs repository, it managed to make a pack that was 50% smaller than the default git pack, and its default bundle was 20% smaller than an agressively (and expensively) packed git pack.
No real need to make bundles
Mercurial’s revlog repository format makes deltas as new revisions are added, avoiding much of the need to make bundles - while sacrificing parallel updates to the same repository (without making entire new clones).
Mercurial Queues
An implementation of the ‘quilt’ pattern with good integration with Mercurial. While git has one of these (well, about three actually - stacked git, guilt and patchy git), it is a hallmark of an extremely advanced VCS.
What Subversion has over git
Partial checkouts
Yeah. This one’s an open question. There are so many answers and none of them are particularly good. Well, a good thing that even the KDE repository fits on a single DVD when converted to git. (I did have 623,354 revisions online once, but took it down as gitweb died - it was 7,491,252,858 bytes, a Dual-Layer-DVD, a few hundred thousand commits from the finish line, but I have found repositories tend to shrink as each press goes on, as history is correlated and the delta compression starts finding even better deltas). It’s large, but definitely distributable. It won’t fit on the built-in hard-drive on my EeePC, but 8GB of space for it is only $3.50 out of the purchase price of my last three and a half inch.
It’s currently a TODO item in git, but no-one really gives a damn because git’s so darned efficient and networks are fast.
It’s possible to fix this. They solved an analogous problem with shallow clones (see git-clone(1)). It’s just not been a priority for many people.
svn:externals
There is support for submodules since version 1.5.3, but it’s still in early stages. This would also provide another way to solve the above problem with partial checkouts - big projects could put pieces into sub-projects, which would be able to be cloned separately.
Summary
We have the tools we need to break away from centralisation! Now, we just need to convert the 10,000 projects…
git’s not the tool for every occasion. I’d certainly recommend that people consider at least Bazaar-NG and Mercurial. Or darcs if they’re developing projects in a University in Haskell. There’s certainly been a lot of feature cross-pollenation between these systems of late. bzr stole gitk as bzr vis, and via bzr-svn you can even use it to visualise remote SVN urls. Neat!
Apologies that this tutorial kind of slipped into becoming an advocacy article, I hope that there are enough pointers and commands along the way to get those interested in git-svn on the right track.
Epilogue on history rewriting
Earlier in this article I referred to history rewriting in passing. I include this as a pointer for the keen, but bear in mind that this falls into the class of “history munging”, and for various reasons is best done in the privacy of an unpublished project.
Let’s say that we have a branch (the current one) that contains all the patches that we want to move to a rebased history.
We manually find a common commit (possibly using gitk). Let’s say it was commit 7cbf53525bc6387495edd574ecdb248e1e4f872a, which became aa3e7febb0477e15257c89126d037f6f81a7974c. You’d re-write that using git-filter-branch:
$ git filter-branch -k 7cbf53 \
--tag-name-filter 'cat' \
--parent-filter "sed -e 's/7cbf53525bc6387495edd574ecdb248e1e4f872a/aa3e7febb0477e15257c89126d037f6f81a7974c/'" \
new-branch
That’s a one-line history graft. I’m not even going to start explaining it.
Update: except that to say, you could do the same thing much more simply and safely now with grafts; assuming you wanted to make aa3e7febb047 the new ancestor of commit ea2fef5f7ca:
$ echo ea2fef5f7ca978985d5a741d448009c5e577e080 \
aa3e7febb0477e15257c89126d037f6f81a7974c > .git/info/grafts
$ gitk --all # (look right?)
$ git filter-branch --tag-name-filter 'cat' --all
Of course you have to be careful with this kind of history munging, you might just end up with somebody wondering why their “git-pull” is taking so long to negotiate which commits it has and hasn’t got, and watch out for the dreaded message “warning: no common commits” issued by git-fetch.
Other things that you end up doing when history munging are identifying and tagging instances of cherry picking between branches; spotting merge points and re-writing the parents to represent the merge correctly, removing dummy commits, and even retrospectively applying automatic coding standards. Usually the overriding principles are:
- It should be possible to get back exactly the old state, but..
- I don't want anything distracting, irrelevant and untidy in the revisions I normally query for version history, and
- I probably only care about being able to build revisions which are relatively near recent history (so, retrospective whitespace cleanups using tidy'ing tools are ok)
- Save the old revisions for safekeeping, in a sepatate repository (that could refer to the latest one for alternates) for large rewrites, and using non-standard refs (eg, instead of refs/tags/Foo, use refs/Attic/Foo) in the same repository for small rewrites.
As git repositories can store separate branches that do not share tangible history, you end up with not only a sequence of commits, but a series of histories, each successively more useful for mining than the older one.
Coding standards, such as whitespace, indenting, line feeds, etc, can really throw a spanner in the works when trying to identify which change introduced a line of code (ie, to answer the question, “why is this line of code here?”). Instead of finding the initial revision, you stop on some change where somebody decided to reformat the code or somebody accidentally pressed tab on a line somewhere. The kind of thing that irritates people on projects with review procedures, because there is a trivial, unnecessary change which they have to skip over. After this kind of munging, hopefully they become transparent to historical querying - because the versions before and after are indented (or whatever) in the same way.
Repairing the damage done to projects by crappy version control systems can be a large, open-ended task, so be careful which projects you take on (Update: finished!). Just ask Shawn Pearce, who ended up writing a new packfile format because git didn’t save enough space with the Mozilla repository. Well, at least it didn’t balloon it to 8.2GB like Subversion did.
Contributors
Thanks to all the people who have given me feedback and thanks for writing this document. For the complete and accurate list of credits, please refer to the git log - pull from here.
These people get acclaim on this section for submitting me well written patches and/or pull sources that I could just merge:
- Jakub Narebski
- Stijn Hoop
- Bart van Bragt
- Ask Bjørn Hansen
