(with apologies to mnftiu)
Ok, so I’ve been working on this program to convert the Perl history from Perforce, with the view to tack it on top of the previous conversion I worked on.
Today, I had my first successful run that includes converting the integration data. It’s a huge milestone for this project - which I initially agreed with Nicholas Clark to undertake way way back in August 2006 over a pint on the banks of the river Thames. I was on my way back from my Catalyst sponsored visit to Birmingham for YAPC::Europe. I certainly didn’t think I’d be still working on it a good 16 months later.
This latest conversion is based on reverse engineering Perforce ’s back-end. In addition to its binary data files, it keeps a nice, simple journal file and periodically checkpoints all the data in the database, and uses RCS files for holding actual file data. This makes importing a “simple” matter of loading its checkpoint/journal files into a database, and writing a few queries. Getting all the file images out was easy enough - and I used the git fast-import interface, and within a few days of working on it came up with a version that would export all of the files for the 30k-odd revisions in the Perl repository (over 225k distinct images in about 20k RCS files) in about 5 minutes on my laptop.
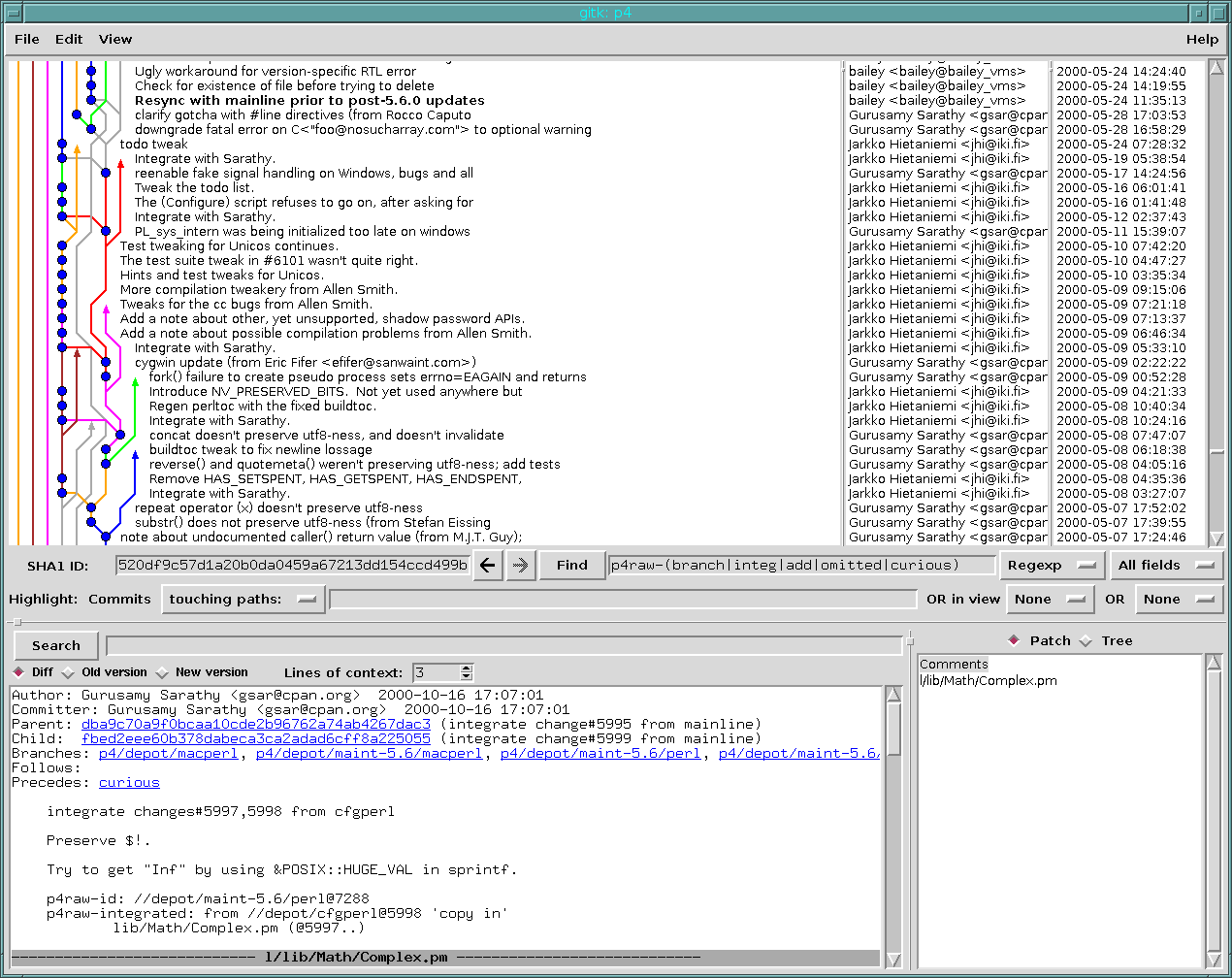
Perforce has a lot of model similarities with Subversion - principally, that it tracks branches in the same namespace used by the filesystem of your project (this “branching is just copying” snake-oil), so that finding the list of branches is not a simple operation. In fact, it may require complicated history analysis. Another similarity is that they both store file history, rather than say tree history like git or a teetering pile of patches like darcs. I’d call Perforce’s engineering quality a lot higher than Subversion, though - the design is quite elegant, it just lacks … well, the underlying simplicity of git. To compare, git has 5 important object types, if you include references, with very few fields. Perforce has 38 tables, and though only a handful of those are really required (my script loads 7 of them), the overall complexity of the schema is far higher.
As a result, managing branched development has been an art known well only to an elite minority of users - which I think do include Perforce users. It’s quite obvious looking through this history that the integration facilities have been there since the repository was imported, and the pumpkings knew how to use them.
The challenge
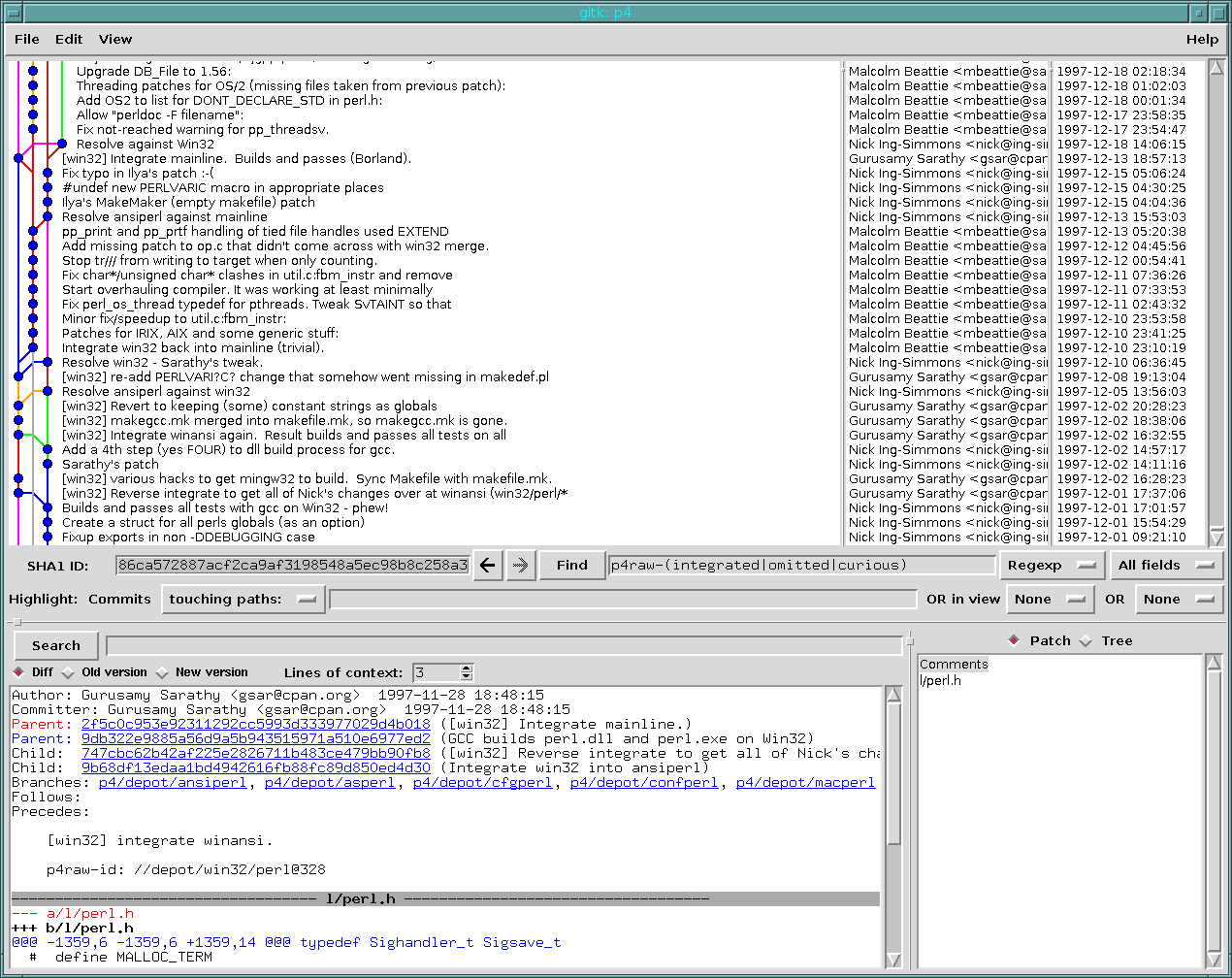
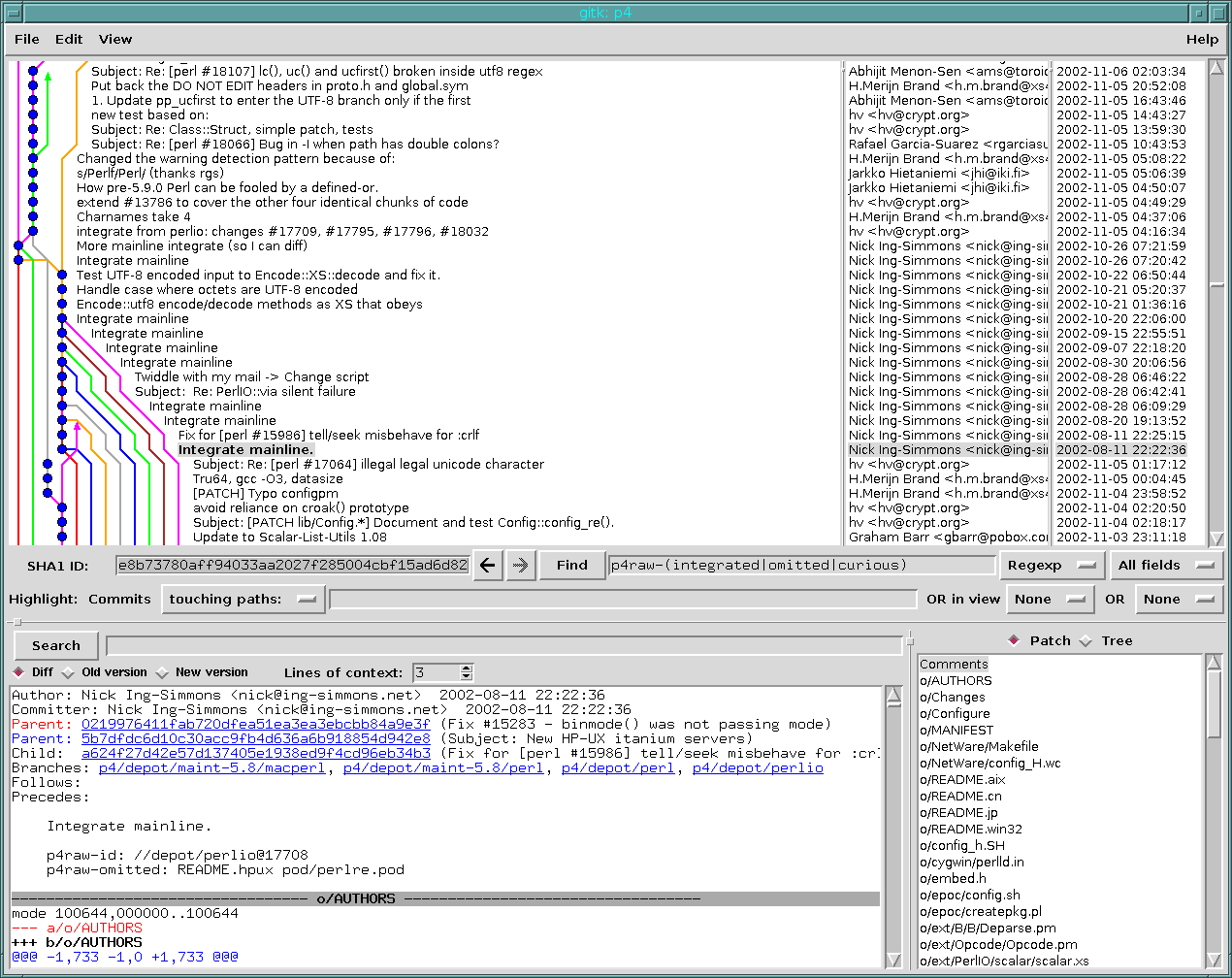
The principle task at hand was to convert the literally hundreds of integration records held in Perforce, and try to convert it into git native format while not throwing any information away that might be important.
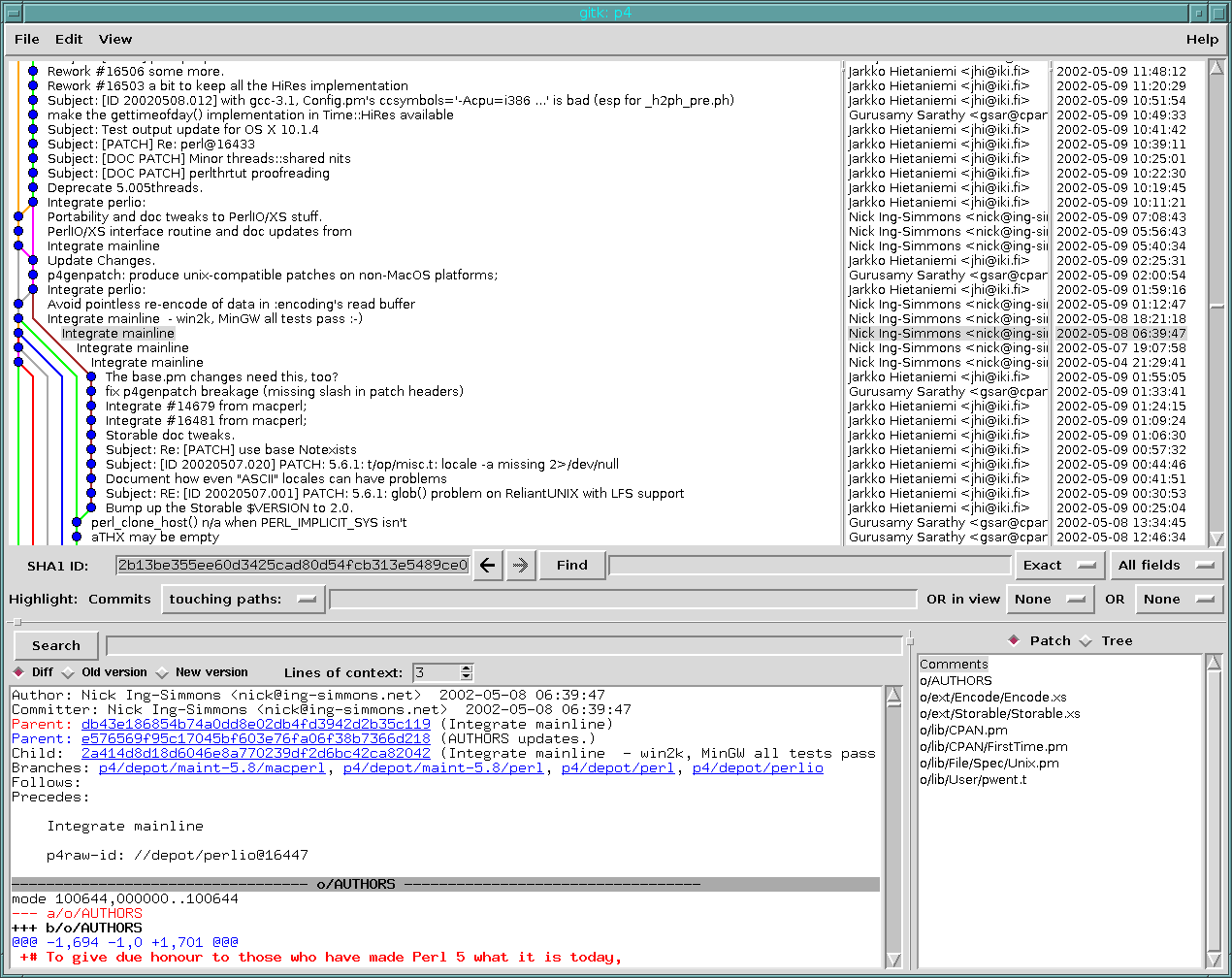
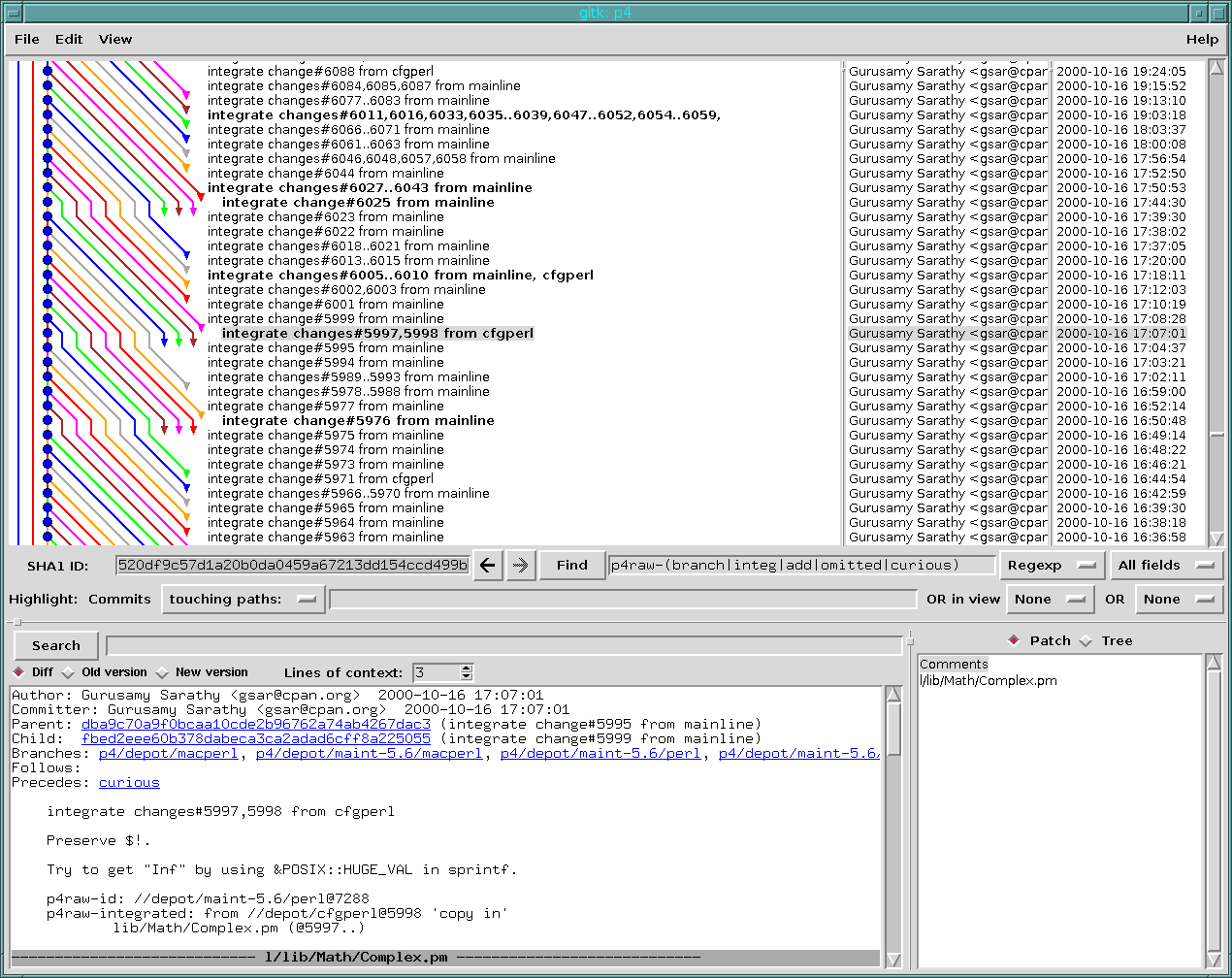
The logic was this - if you see a change in the history, such as “integrate changes from mainline”, and there are a bunch of integration records that seem to indicate that all of the files on the branch you are merging from that have changed since you last merged, have an integration record for them, then you mark that commit as a merge. If this single piece of information agrees with hundreds of per-file records, then you have just simplified the repository, without losing any information. I thought I had this early on with this monster query, but I ran into several problems - the answer to the question “which files are outstanding for merging?” is quite difficult to answer. The first answer I came up with, to just do an index diff between the two trees, only worked for the first integration. I needed to write a merge base function capable of inspecting the history graph. It comes up with a list of changed files since the merge base, and uses that to decide what integration records should be present.
The good news is that it appeared to work very well - a huge portion of the integration information in the history corresponds to complete cross-merges between branches.
The impedence mismatch
One of the biggest concerns is that the so-called “impedence mismatch”, that is, the presence of important information that simply cannot be represented by git’s model.
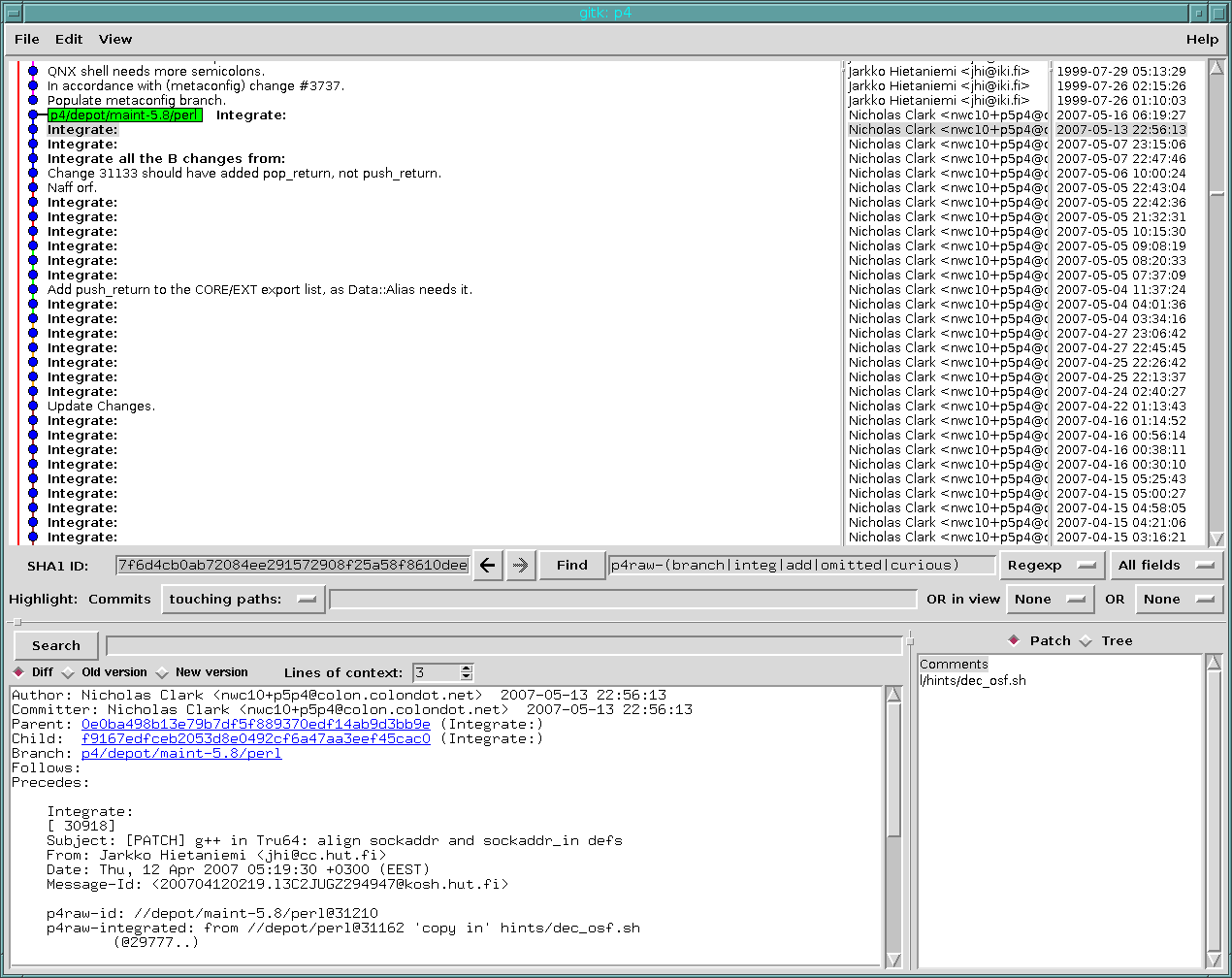
In particular, one thing that you can’t do with just tree tracking is to detect cherry picking, where those cherry picks changed the files along the way. If the cherry picking happened without changes this is easily detectable without any metadata - but if it did change, you either need some kind of fuzzy logic, or you need to record out-of-band what happened.
Git and Perforce couldn’t be more chalk and cheese about this. Perl’s development model is one that a colleague dubbed the ghetto merge model, where you have some kind of “hood” where the “flyist features go to battle it out”. The features left standing are subsequently moved into trailer parks (aka integration branches), where they can make a new life for themselves and prove their stability.
Git does support that model - for instance, Junio Hamano’s proposed updates branch of git could be considered the “unstable” branch, and changes can even be completely dropped from that one. There is a branch called “next” for features which are considered going into the “next” minor release, from which changes are not removed. There is a “maint” branch which bugfixes for existing versions go onto, etc. The key difference here is that changes go in earliest-first, rather than newest-first, with variations between the revisions of them showing up as the stable branches are re-merged into the newer branches. Git’s development model has already proven itself to stimulate innovation and experimentation, as well as the core team being able to produce a very stable product, though of course it is no magic bullet to make it all things to all people.
So, in the face of all of these things, I simply made the program display as much information as it could figure out at each point and ask the presumably infinitely more enlightened user for advice, and as I got bored of answering the questions, built a bit of fuzzy logic into it to make answers based on the rules of thumb that I’d figured out.
Remaining tasks
I’m very grateful to now have direct rsync access to the raw Perforce repository, courtesy of Robrt. With a little refactoring, this “raw” Perforce importer could be generally useful to other people stuck with Perforce who might find themselves completely unable to find a suitable replacement product.
There are always remaining tasks when it comes to Software Archaeology - more information that can be put in etc. For instance, I have not even looked in this conversion at doing the p5p archive scanning that I did for Chip’s pumpking series, which allowed me to represent the difference between a patch submitted and a patch applied. But at some point you have to draw the line and cut a release.
I’ve made some history releases before - but this one is good enough that I know I have to be careful - as it is already highly functional and capable of being used for people who want to track Perl development, or for people with proposed features to develop them on their own feature branches for future pumpkings to manage. Already there are several of these repositories out there with different histories - and so, I’d like to make sure that the next release I make has as much correct author attribution information in there as possible, so that for instance people’s OHLOH stats are correct.
There is still one large chunk of history which while having dozens of releases is only represented by a handful of commits, and will need the scripts used to import Chip Salzenberg’s 5.003 to 5.004 series patches extended to cover the slight variations in release style used by Tim Bunce. That I’d also like to have complete first. It would be nice to have this all finished by the looming 5.10.0 Perl release, but I don’t really want to compromise on correct attributions to do so.
Other than that, I do want to make sure that whenever changes are referenced in commit messages, or the metadata that appears in the commit message, that the corresponding git commit ID is placed in the message - so that you can easily bounce around them in gitk and gitweb.
And then, I think I’ll have achieved what might be the most complex Perforce to Git conversion in the Free Software world to date, as well as liberating the source code for a project which is dear to many people.